Our main research interests include:
- computer vision, surveillance:
crowd analysis, crowd counting, crowd tracking, visual object tracking, multi-view vision, dynamic textures, motion segmentation, motion analysis, image captioning and annotation, image retrieval. - machine learning, pattern recognition:
probabilistic graphical models, deep learning, Bayesian models, Gaussian processes, active learning. - explainable AI (XAI):
gradient-based attribution methods, user trust - eye gaze analysis:
modeling eye movements with hidden Markov models (HMMs), clustering HMMs, co-clustering, DNN+HMM - computer audition, music information retrieval:
semantic music annotation and retrieval, music segmentation. - data-driven computer graphics:
data-driven graphic design, machine learning for graphics.
In particular, we aim to develop machine learning models, such as generative probabilistic models and deep learning models, of images, video, and sound that can be applied to computer vision and computer audition problems, such as crowd monitoring, image understanding, and music understanding. Our current research projects are listed below.
2024
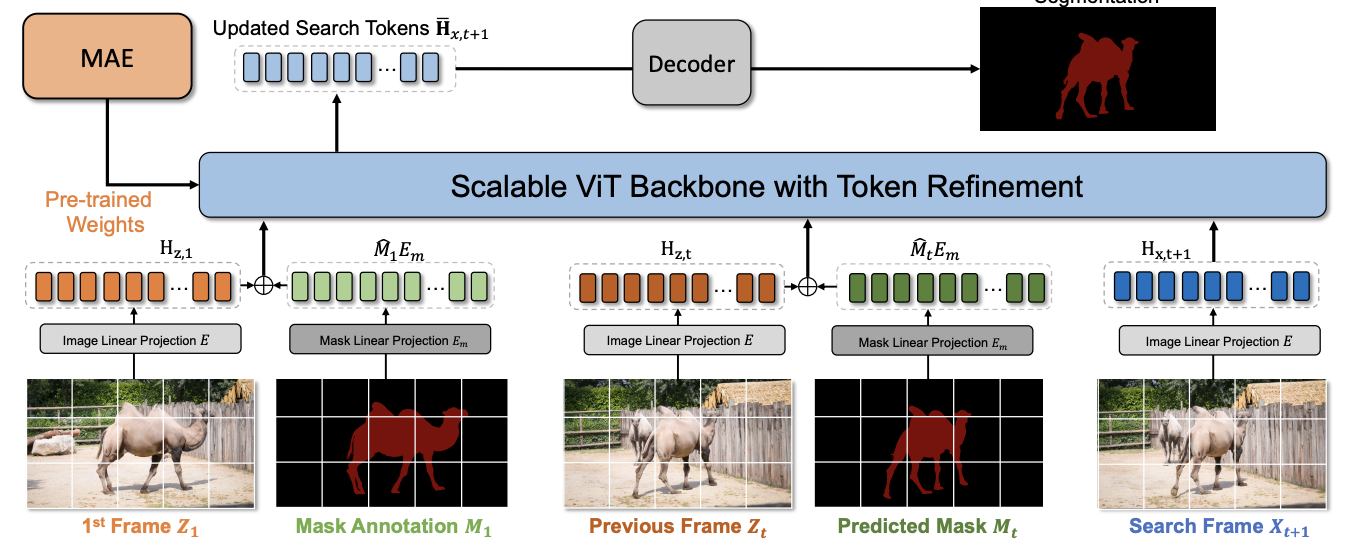
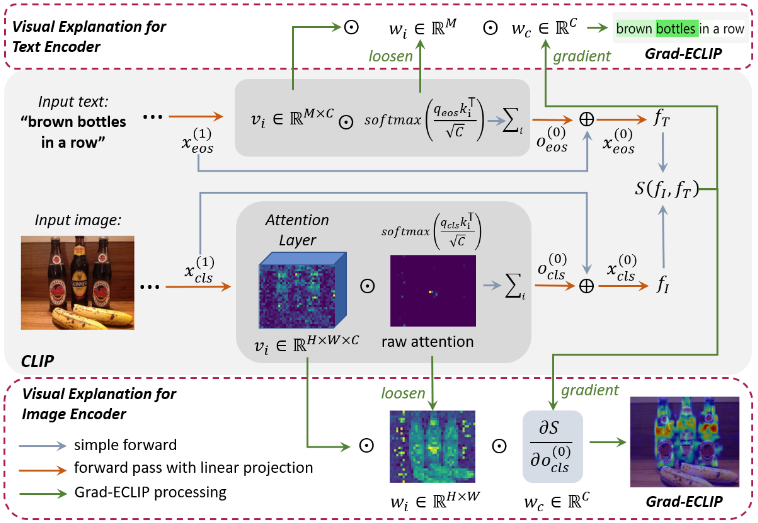
We propose a novel watermarking framework that leverages adversarial attacks to embed watermarks into images via two secret keys (network and signature) and deploys hypothesis tests to detect these watermarks with statistical guarantees. We propose a Simplified VOS framework (SimVOS), which removes the hand-crafted feature extraction and matching modules in previous approaches, to perform joint feature extraction and interaction via a single scalable transformer backbone. We also demonstrate that large-scale self-supervised pre-trained models can provide significant benefits to the VOS task. In addition, a new token refinement module is proposed to achieve a better speed-accuracy trade-off for scalable video object segmentation. We study masked autoencoder (MAE) pre-training on videos for matching-based downstream tasks, including visual object tracking (VOT) and video object segmentation (VOS). We propose a Gradient-based visual Explanation method for CLIP (Grad-ECLIP), which interprets the matching result of CLIP for specific input image-text pair![]()

2023
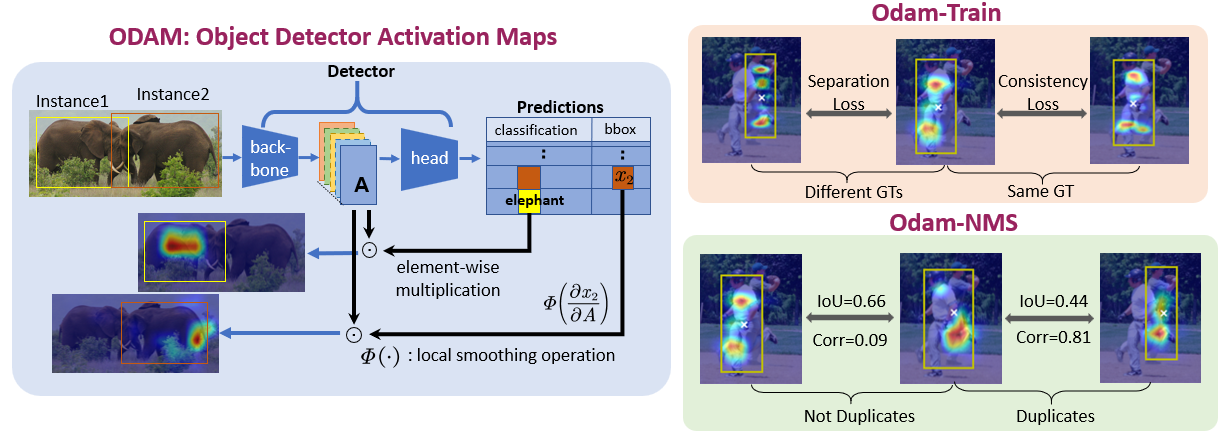
We propose a batch-mode Pareto Optimization Active Learning (POAL) framework for Active Learning under Out-of-Distribution data scenarios. We propose the gradient-weighted Object Detector Activation Maps (ODAM), a visualized explanation technique for interpreting the predictions of object detectors, including class score and bounding box coordinates. We present a comprehensive comparative survey of 19 Deep Active Learning approaches for classification tasks. We introduce an active learning benchmark comprising 35 public datasets and experiment protocols, and evaluate 17 pool-based AL methods.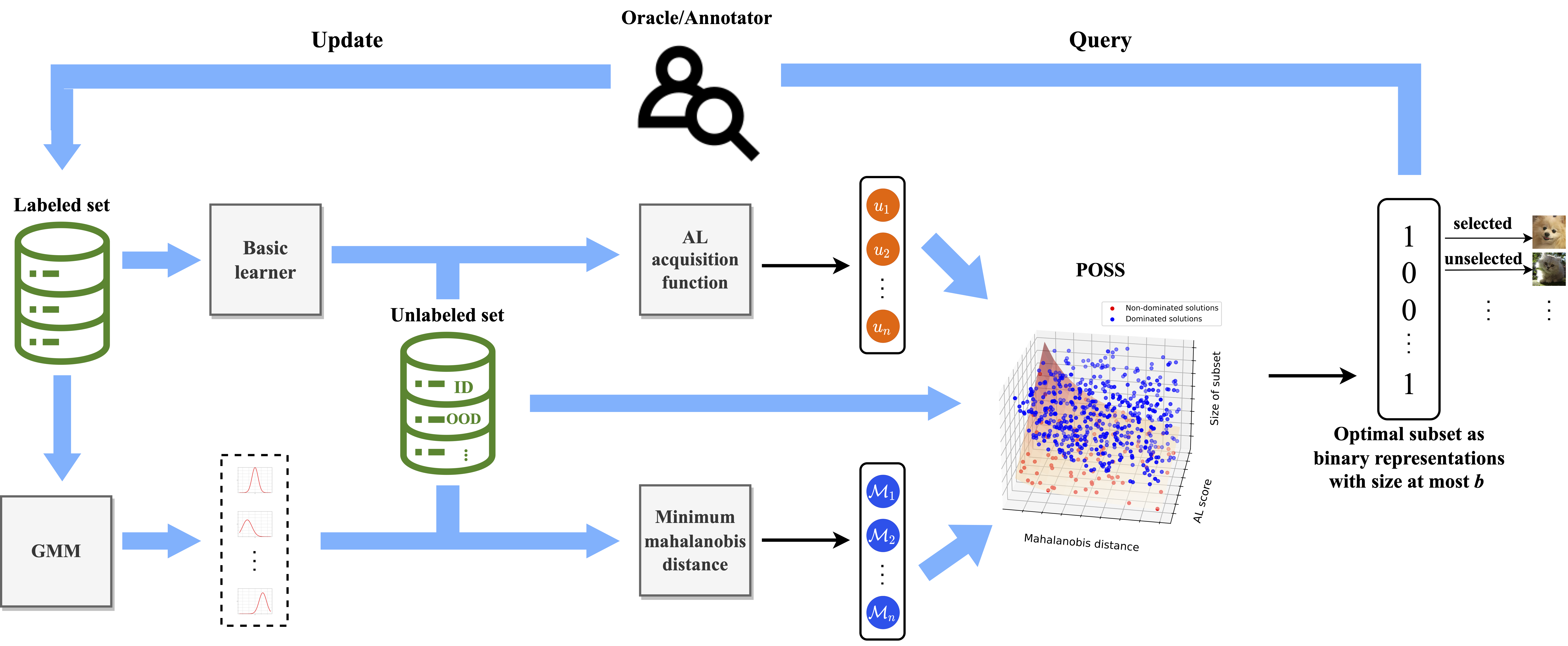
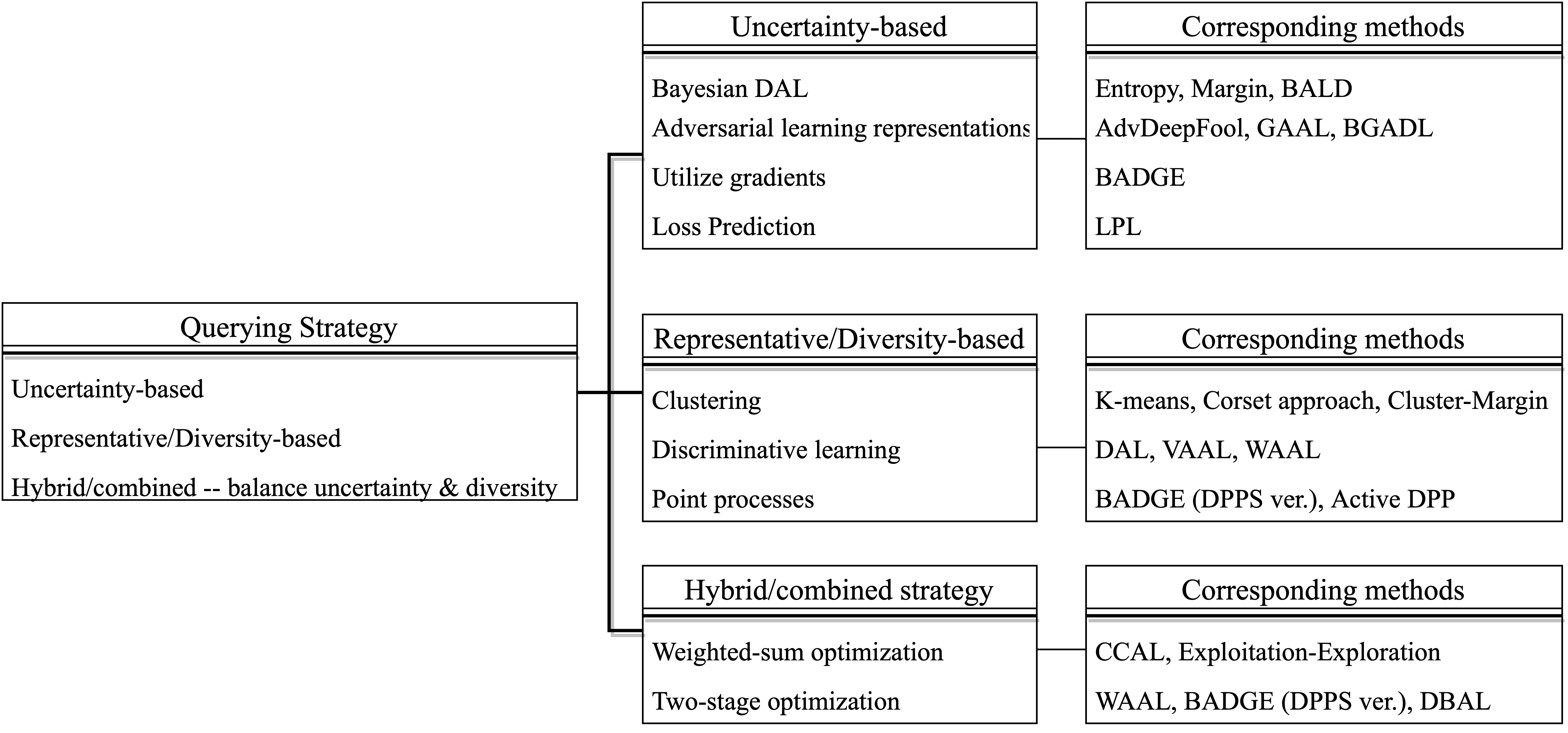
2022
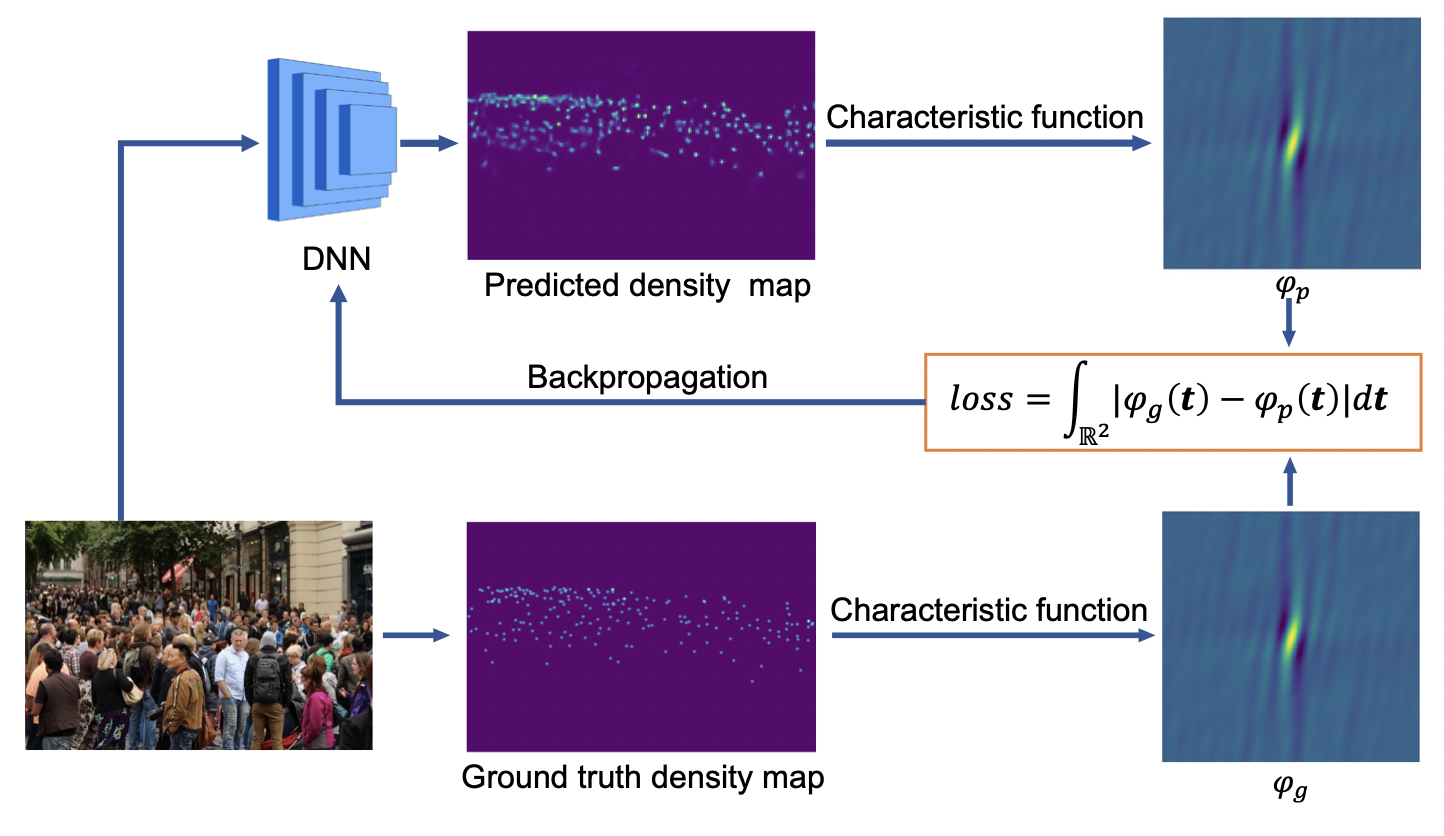
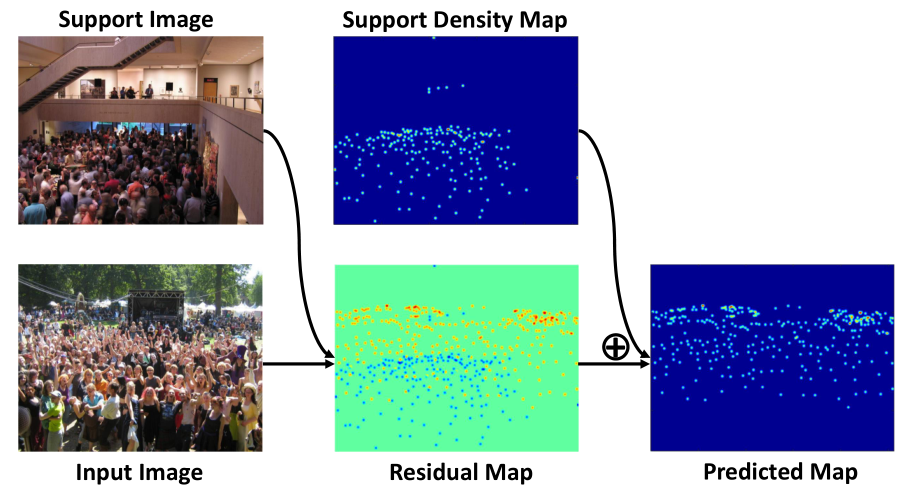
We propose a calibration-free multi-view crowd counting (CF-MVCC) method, which obtains the scene-level count as a weighted summation over the predicted density maps from the camera-views, without needing camera calibration parameters. We propose a synchronization model that operates in conjunction with existing DNN-based multi-view models to allow them to work on unsynchronized data. We model eye movements on faces through integrating deep neural networks and hidden Markov Models (DNN+HMM). We derive loss functions in the frequency domain for training density map regression for crowd counting.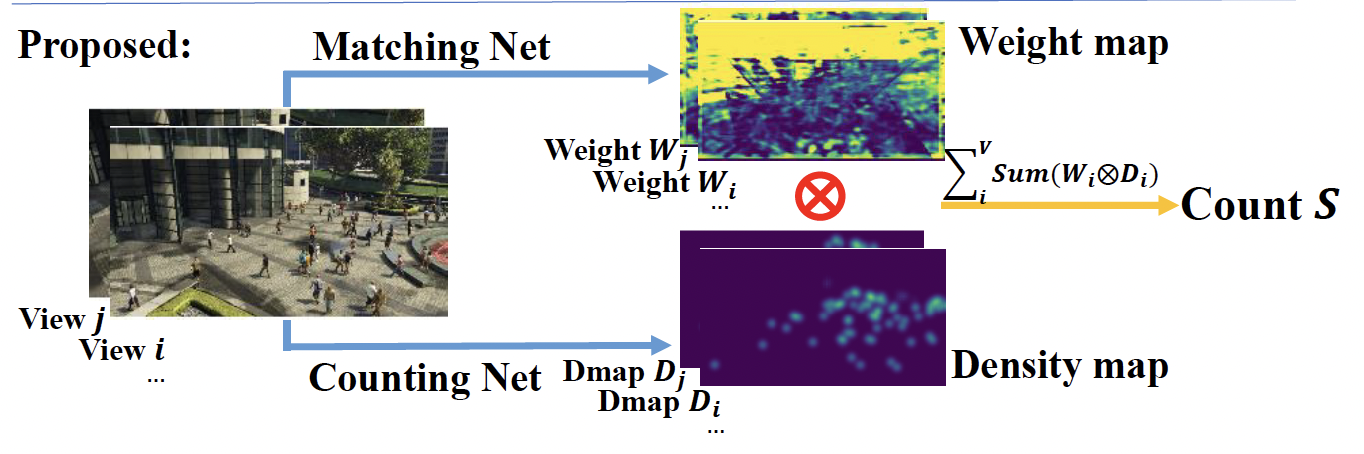
![]()
![]()
2021
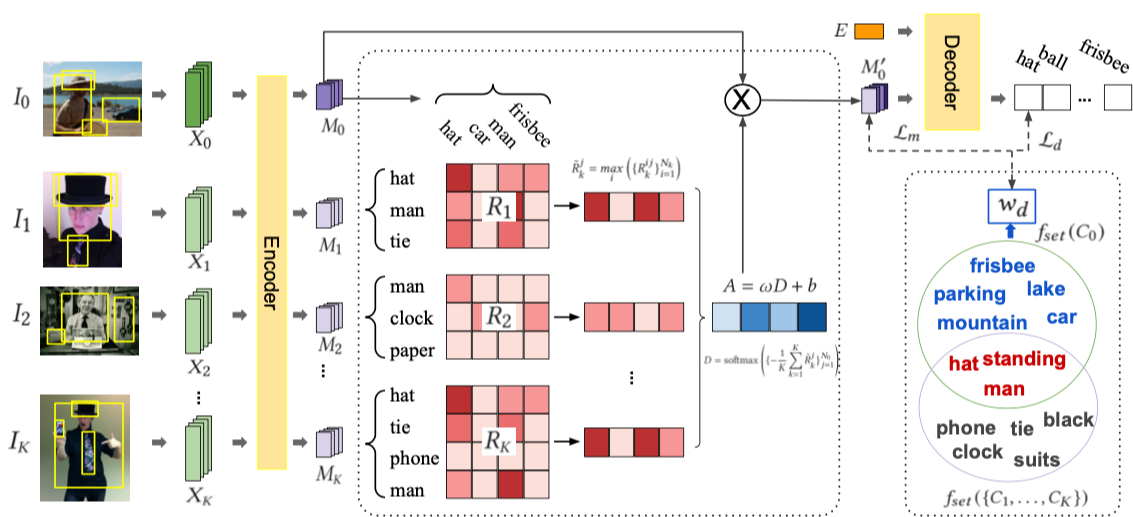
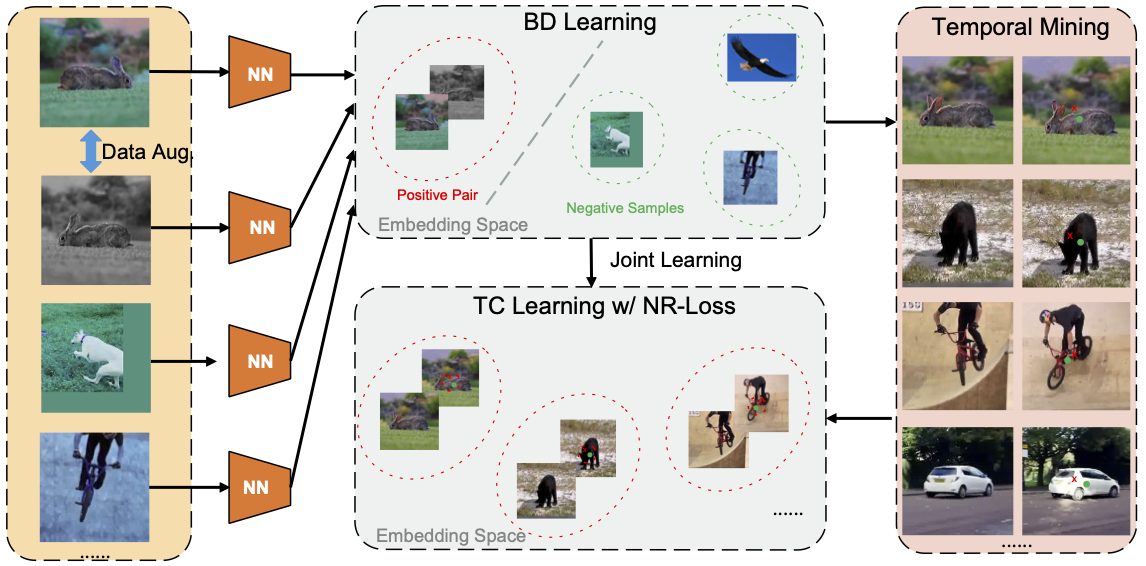
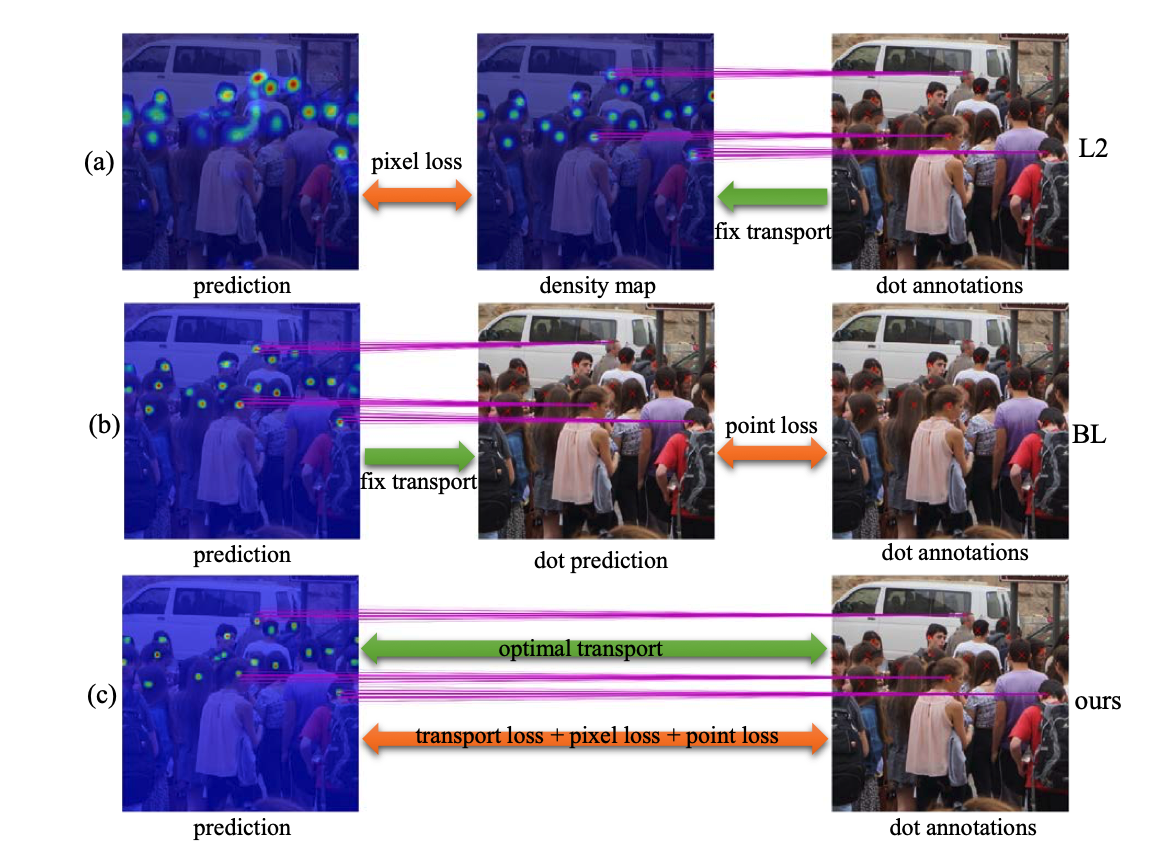
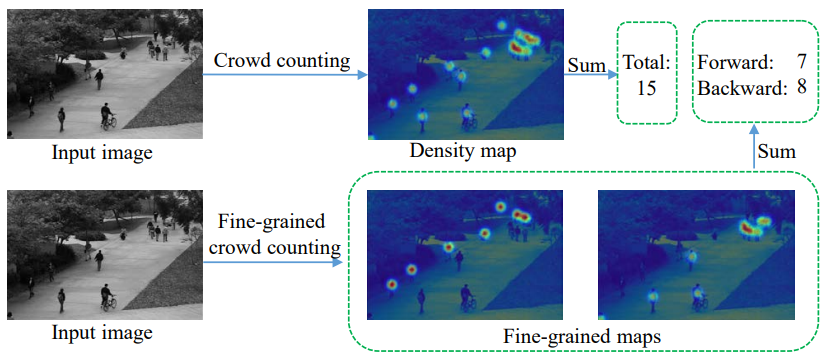
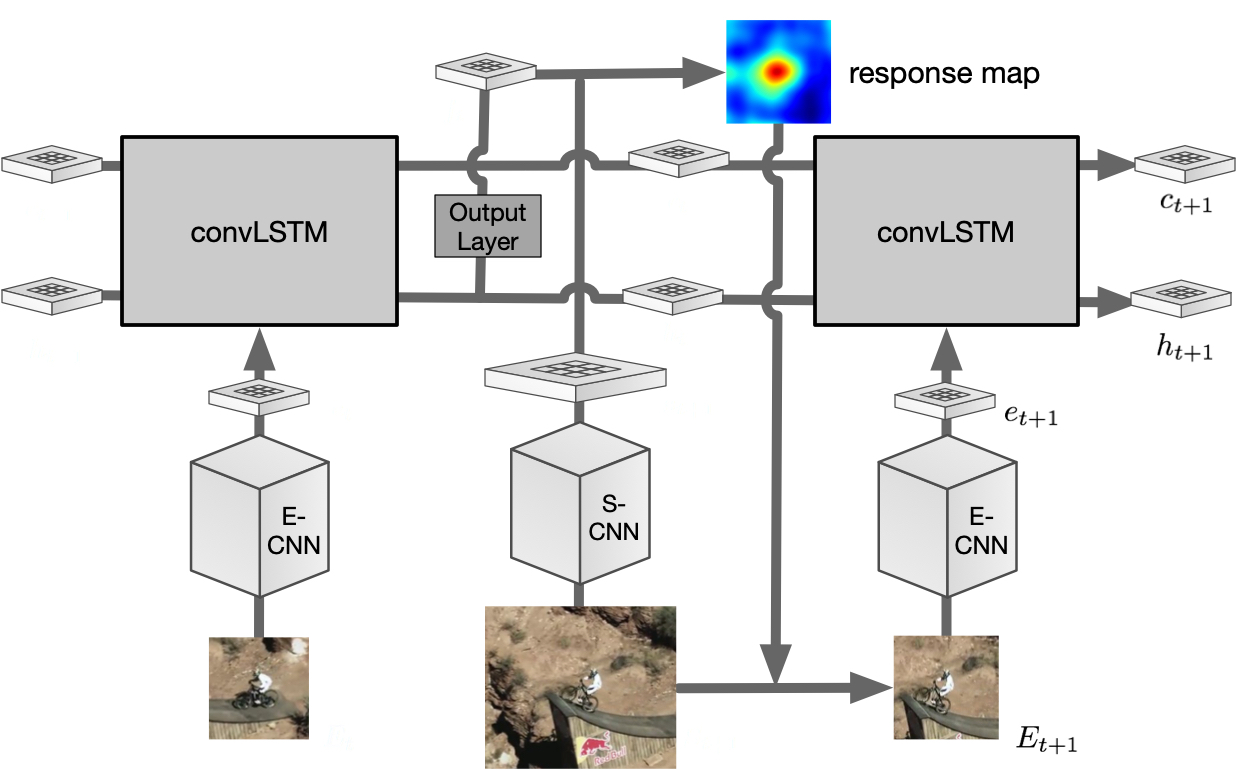
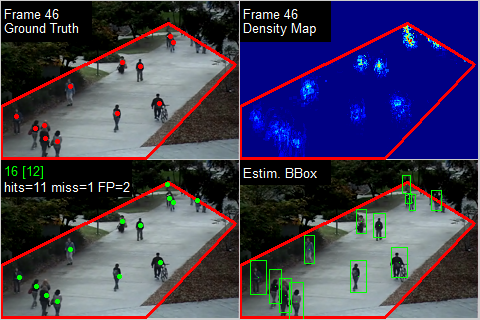
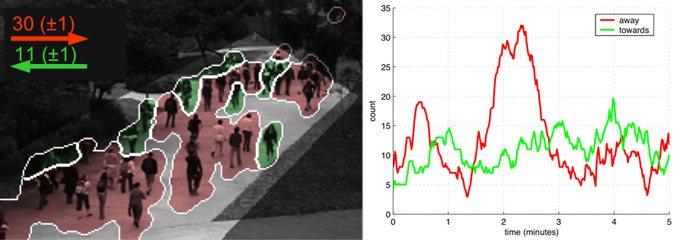
We propose a novel Crowd Counting framework built upon an external Momentum Template, termed C2MoT, which enables the encoding of domain specific information via an external template representation. We improve the distinctiveness of image captions using a Group-based Distinctive Captioning Model (GdisCap), which compares each image with other images in one similar group and highlights the uniqueness of each image. We propose a novel tree structure variational Bayesian method to learn the individual model and group model simultaneously by treating the group models as the parents of individual models, so that the individual model is learned from observations and regularized by its parents, and conversely, the parent model will be optimized to best represent its children. To reduce the human experts’ workload and improve the observation We analyze eye movement data on stimuli with different feature layouts. Through co-clustering HMMs, we discover common strategies on each stimuli and cluster subjects with similar strategies. In this paper, we propose a novel meta-graph adaptation network (MGA-Net) to effectively adapt backbone feature extractors in existing deep trackers to a specific online tracking task. In this paper, we propose a progressive unsupervised learning (PUL) framework, which entirely removes the need for annotated training videos in visual tracking. We propose a fully nested neural network (FN3) that runs only once to build a nested set of compressed/quantized models, which is optimal for different resource constraints. We then propose a Bayesian version that estimates the ordered dropout hyperparameter and has well calibrated uncertainty. We propose a generalized loss function for density map regression based on unbalanced optimal transport. We prove that pixel-wise L2 loss and Bayesian loss are special cases and sub-optimal solutions to our proposed loss. Since the predicted density will be pushed toward annotation positions, the density map prediction will be sparse and can naturally be used for localization. In this paper, we propose a cross-view cross-scene (CVCS) multi-view crowd counting paradigm, where the training and testing occur on different scenes with arbitrary camera layouts. In this paper, we propose fine-grained crowd counting, which differentiates a crowd into categories based on the low-level behavior attributes of the individuals (e.g. standing/sitting or violent behavior) and then counts the number of people in each category. To enable research in this area, we construct a new dataset of four real-world fine-grained counting tasks: traveling direction on a sidewalk, standing or sitting, waiting in line or not, and exhibiting violent behavior or not. We propose a new multiple-object tracking (MOT) paradigm, tracking-by-counting, tailored for crowded scenes. Using crowd density maps, we jointly model detection, counting, and tracking of multiple targets as a network flow program, which simultaneously finds the global optimal detections and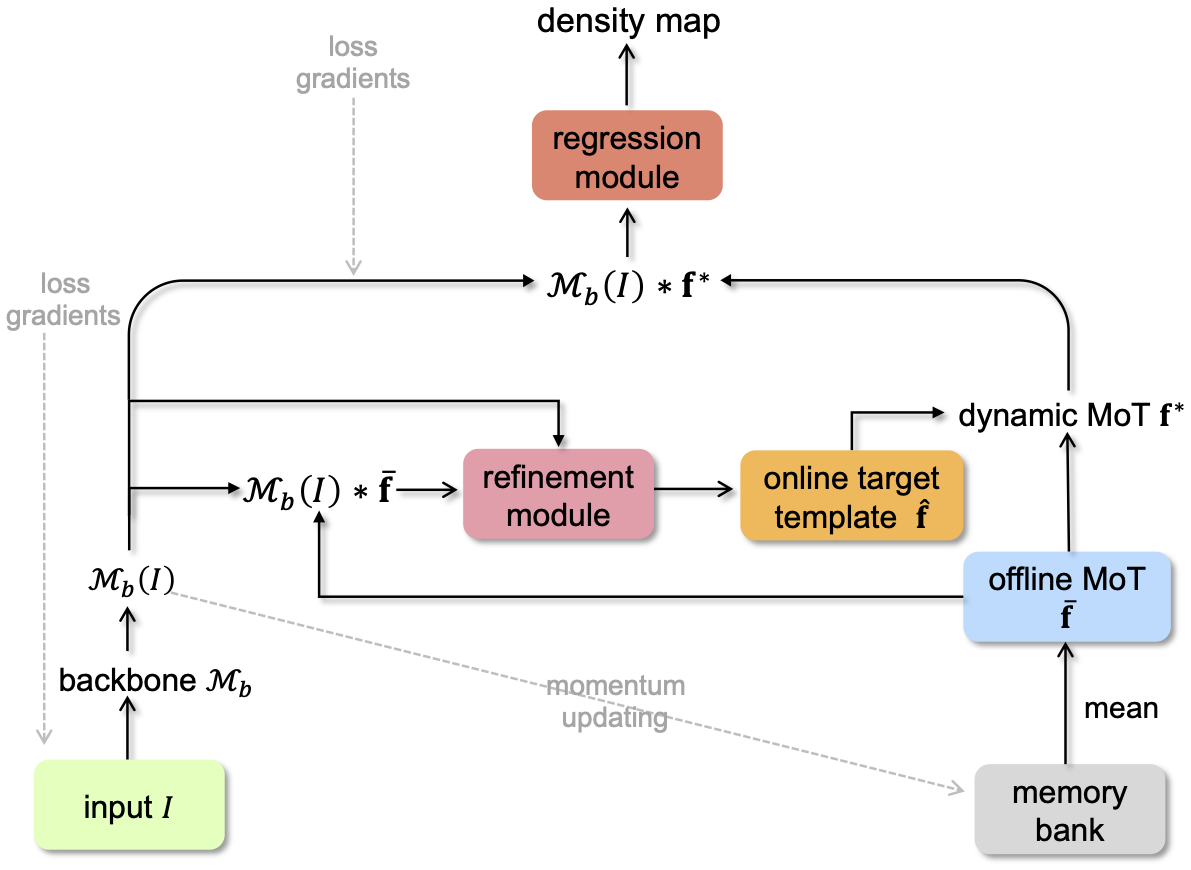
accuracy, in this paper, we develop a practical system to detect Chinese White Dolphins in the wild automatically.![]()
![]()
![]()

trajectories of multiple targets over the whole video.![]()
2020
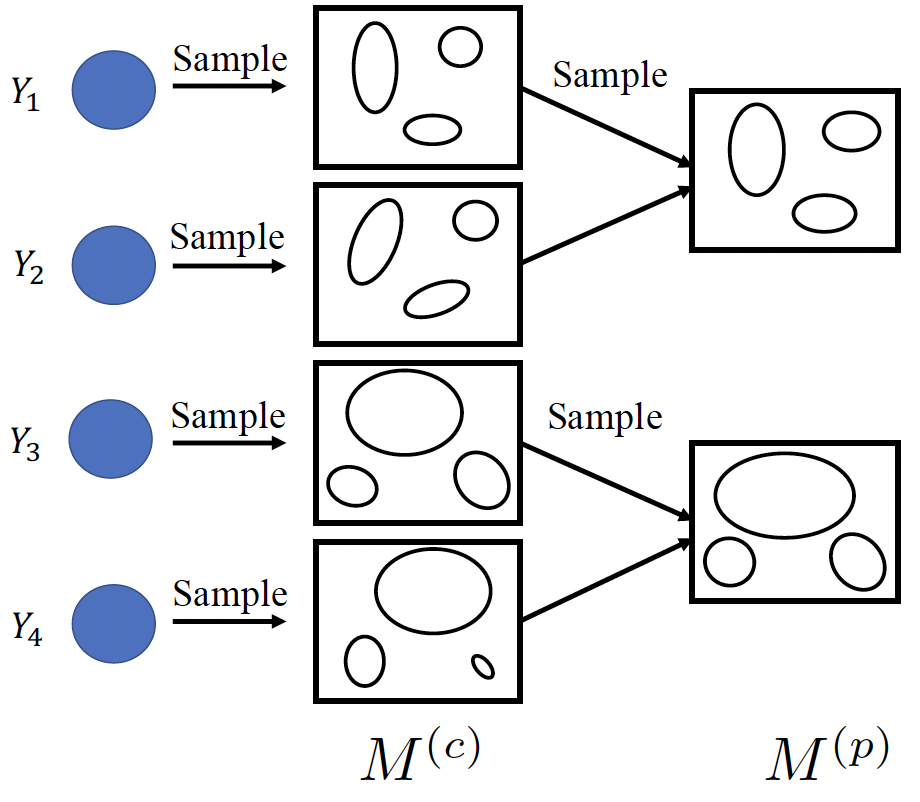
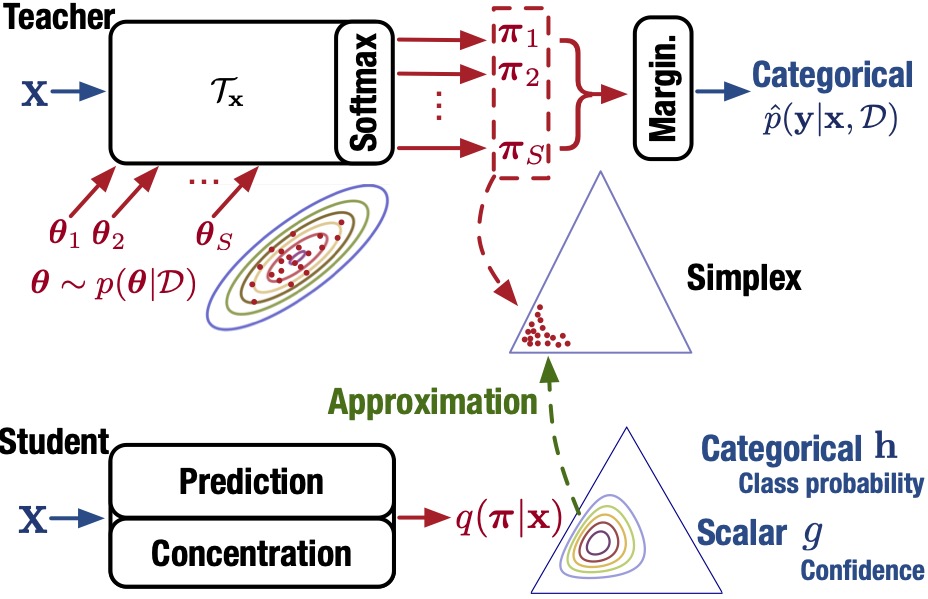
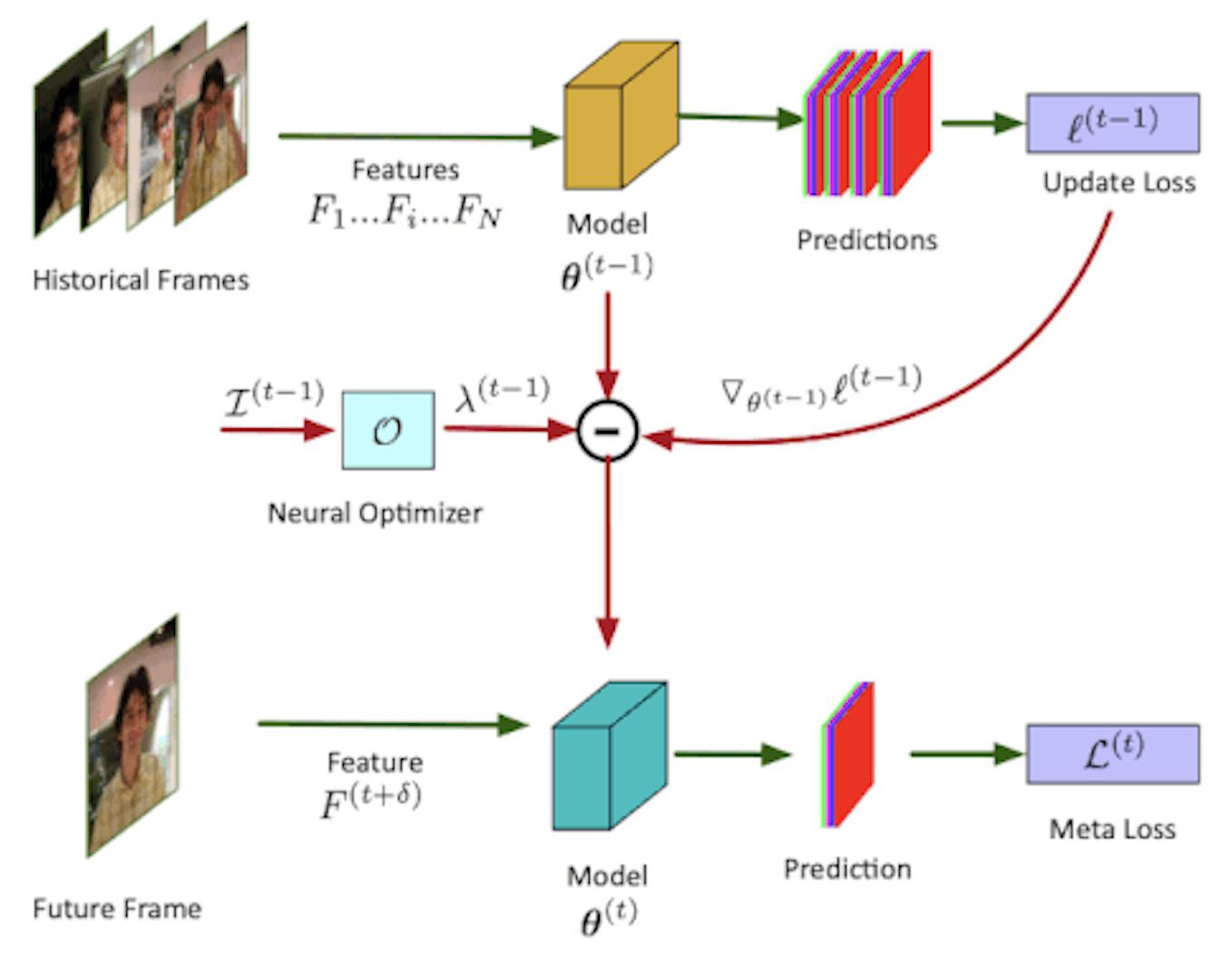
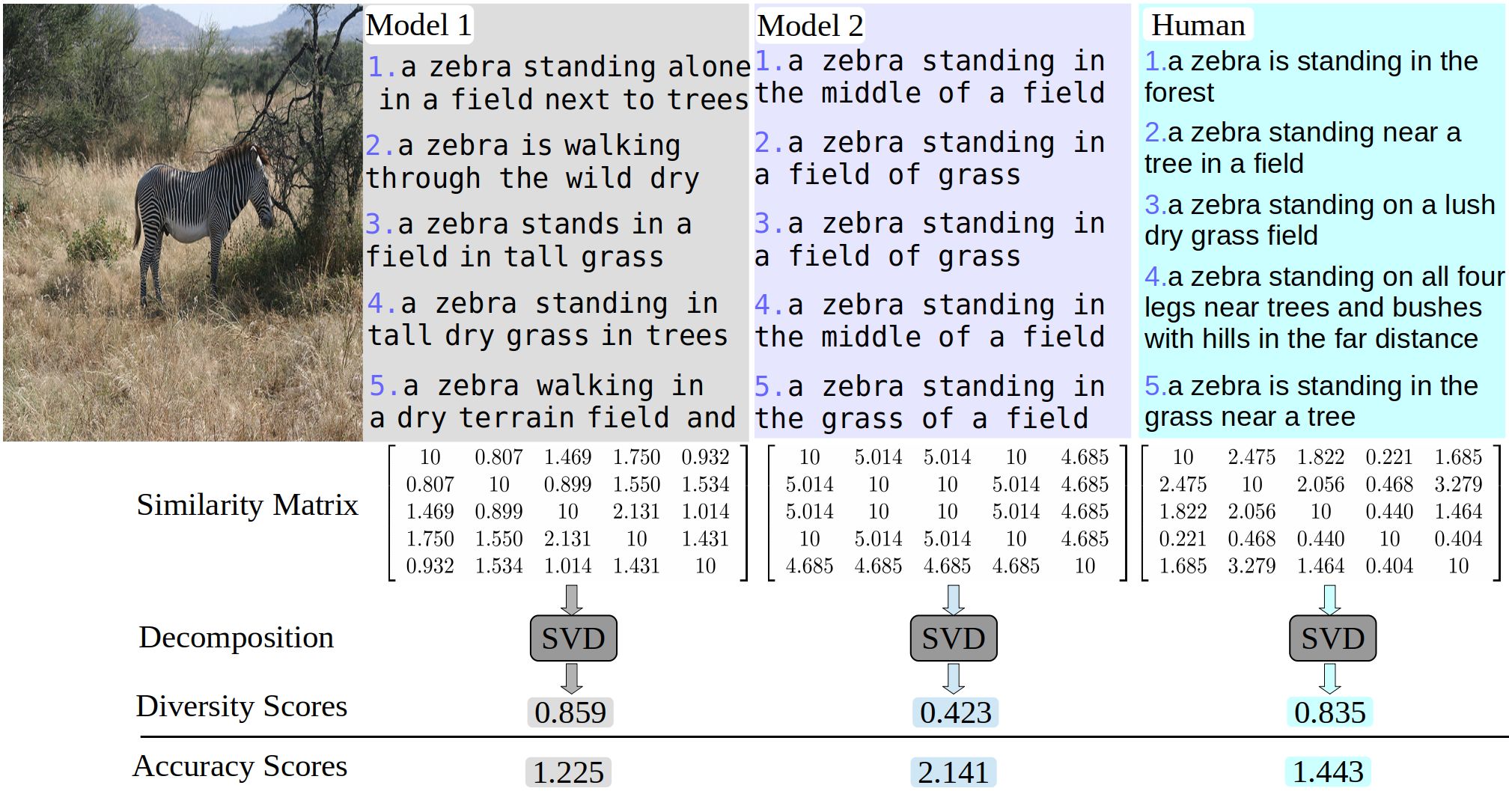
We model the annotation noise using a random variable with Gaussian distribution and derive the pdf of the crowd density value for each spatial location in the image. We then approximate the joint distribution of the density values (i.e., the distribution of density maps) with a full covariance multivariate Gaussian density, and derive a low-rank approximate for tractable implementation. We propose a generic framework to approximate the output probability distribution induced by a Bayesian NN model posterior with a parameterized model and in an amortized fashion. The aim is to approximate the predictive uncertainty of a specific Bayesian model, meanwhile alleviating the heavy workload of MC integration at testing time. To improve the distinctiveness of image captions, we first propose a metric, between-set CIDEr (CIDErBtw), to evaluate the distinctiveness of a caption with respect to those of similar images, and then propose several new training strategies for image captioning based on the new distinctiveness measure. We propose to offline train a recurrent neural optimizer to update a tracking model in a meta-learning setting, which can converge the model in a few gradient steps during online training.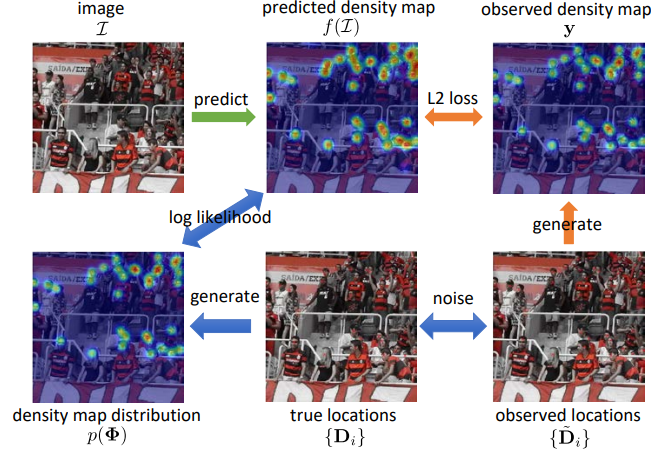
![]()
2019
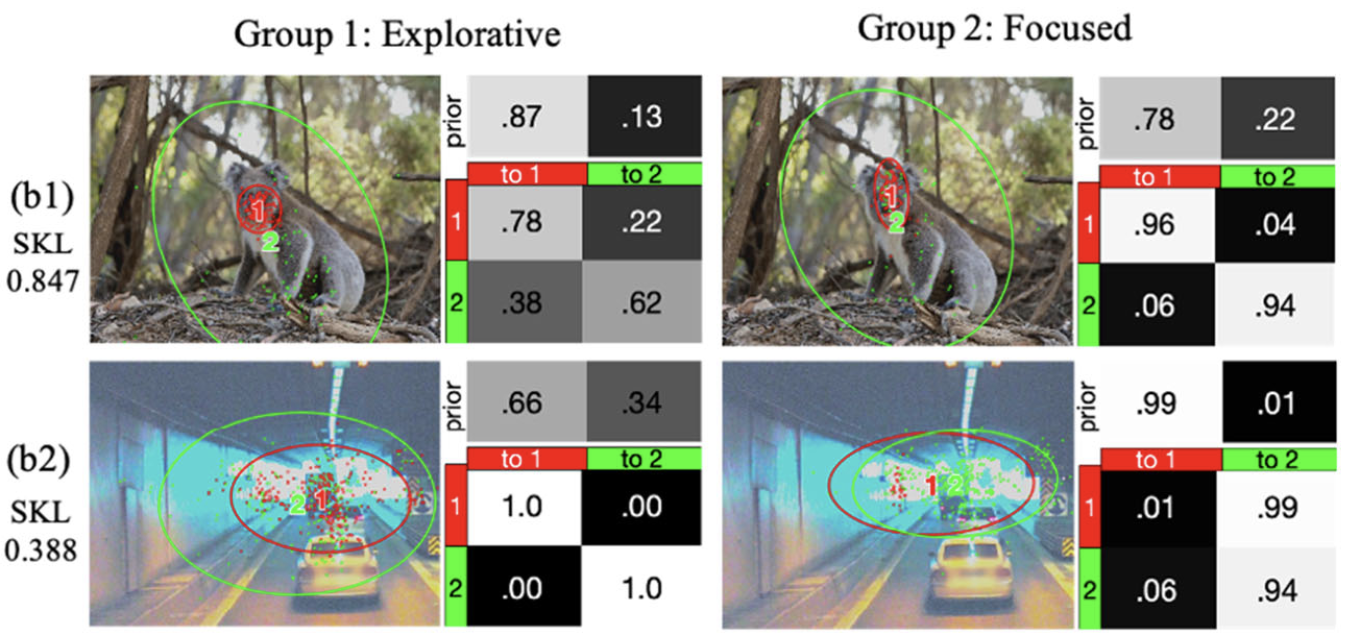
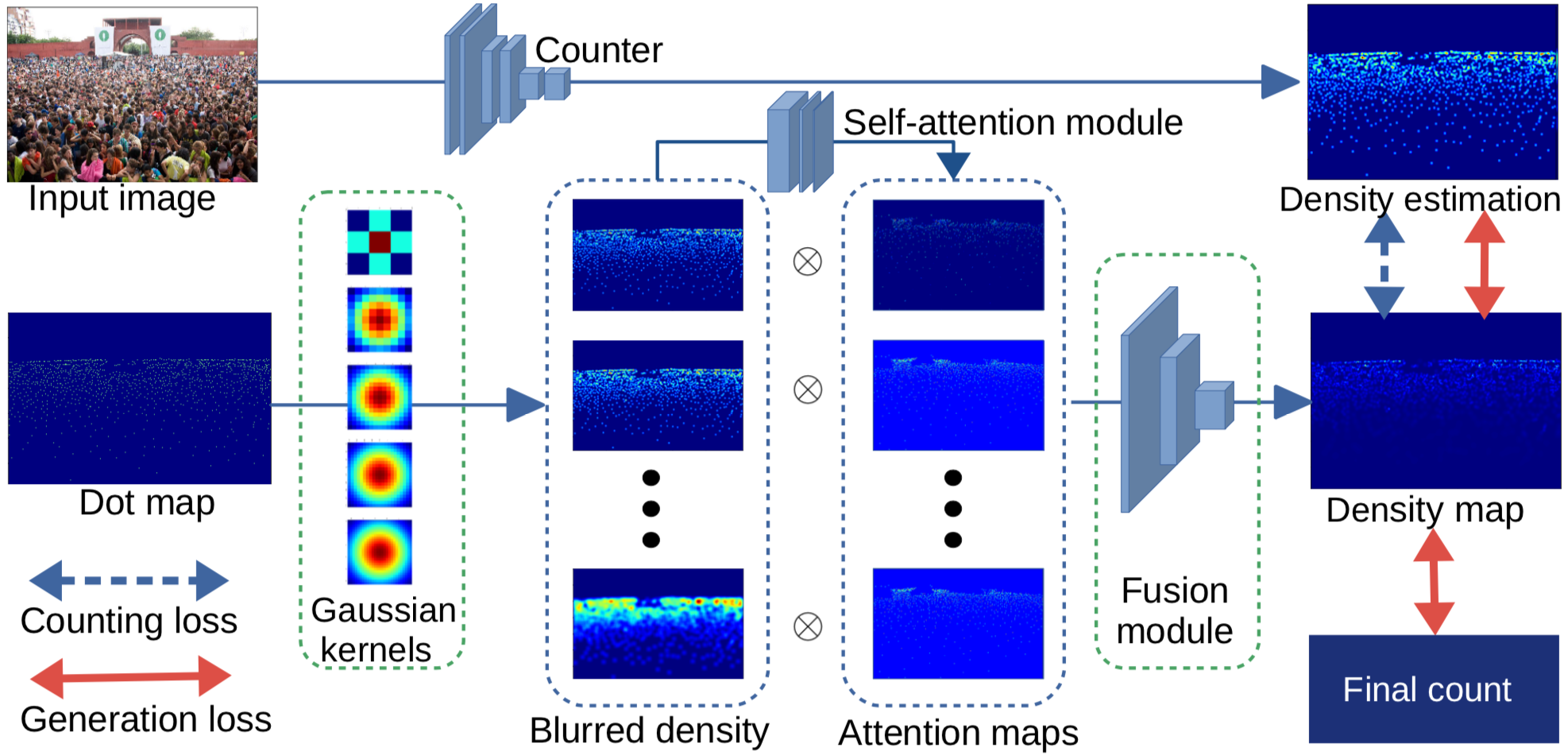
Recently, an end-to-end multi-view crowd counting method called multi-view multi-scale (MVMS) has been proposed, which fuses multiple camera views using a CNN to predict a 2D scene-level density map on the ground-plane. Unlike MVMS, we propose to solve the multi-view crowd counting task through 3D feature fusion with 3D scene-level density maps, instead of the 2D ground-plane ones. In the sense of end-to-end training, the hand-crafted methods used for generating the density maps may not be optimal for the particular network or dataset used. To address this issue, we propose an adaptive density map generator, which takes the annotation dot map as input, and learns a density map representation for training a counter. The counter and generator are trained jointly within an end-to-end framework. We use a switching hidden Markov model (EMSHMM) approach to analyze eye movement data in cognitive tasks involving cognitive state changes. A high-level state captures a participant’s cognitive state transitions during the task, and eye movement patterns during each high-level state are summarized with a regular HMM. We propose a ParametRIc MAnifold Learning (PRIMAL) algorithm for Gaussian Mixtures Models (GMM), assuming that GMMs lie on or near to a manifold that is generated from a low-dimensional hierarchical latent space through parametric mappings. Inspired by Principal Component Analysis (PCA), the generative processes for priors, means and covariance matrices are modeled by In this project, we focus on the diversity of image captions. First, diversity metrics are proposed which is more correlated to human judgment. Second, we re-evaluate the existing models and find that (1) there is a large gap between human and the existing models in the diversity-accuracy space, (2) using reinforcement learning (CIDEr reward) to train captioning models leads to improving accuracy but reduce diversity. Third, we propose a simple but efficient approach to balance diversity and accuracy via reinforcement learning—using the linear combination of cross-entropy and CIDEr reward. In this paper, a residual regression framework is proposed for crowd counting harnessing the correlation information among samples. By incorporating such information into our network, we discover that more intrinsic characteristics can be learned by the network which thus generalizes better to unseen scenarios. Besides, we show how to effectively leverage the semantic prior to improve the performance of crowd counting. In this paper, we propose a deep neural network framework for multi-view crowd counting, which fuses information from multiple camera views to predict a scene-level density map on the ground-plane of the 3D world. 
their respective latent space and parametric mapping.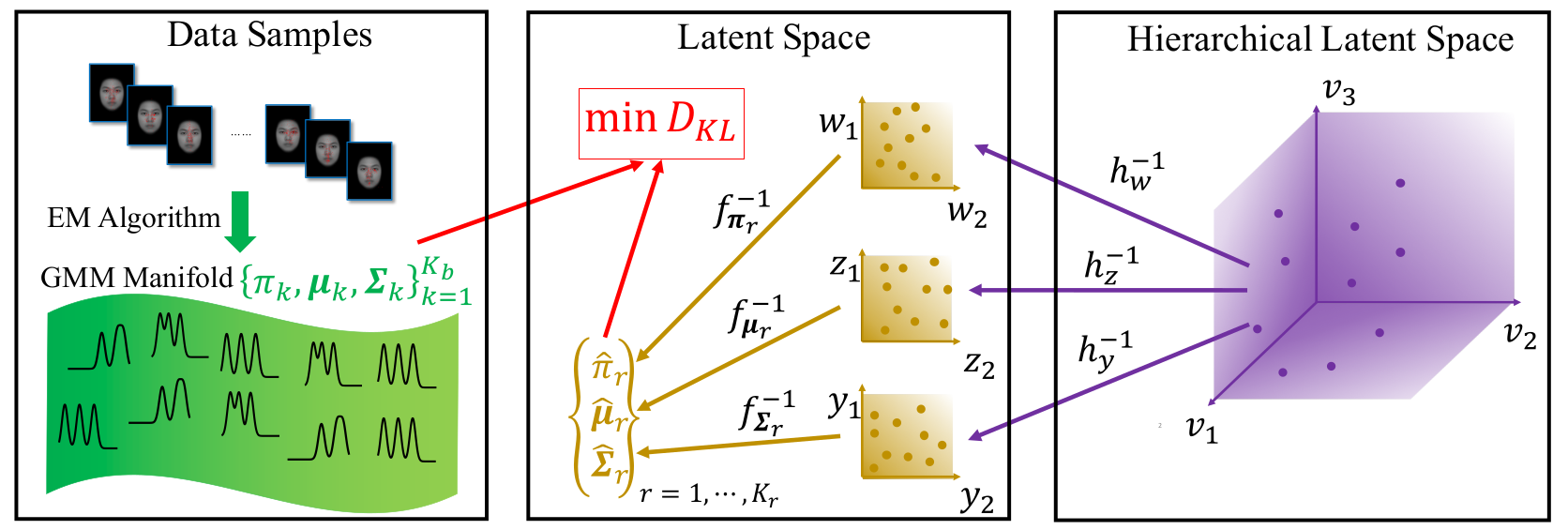
![]()
2018
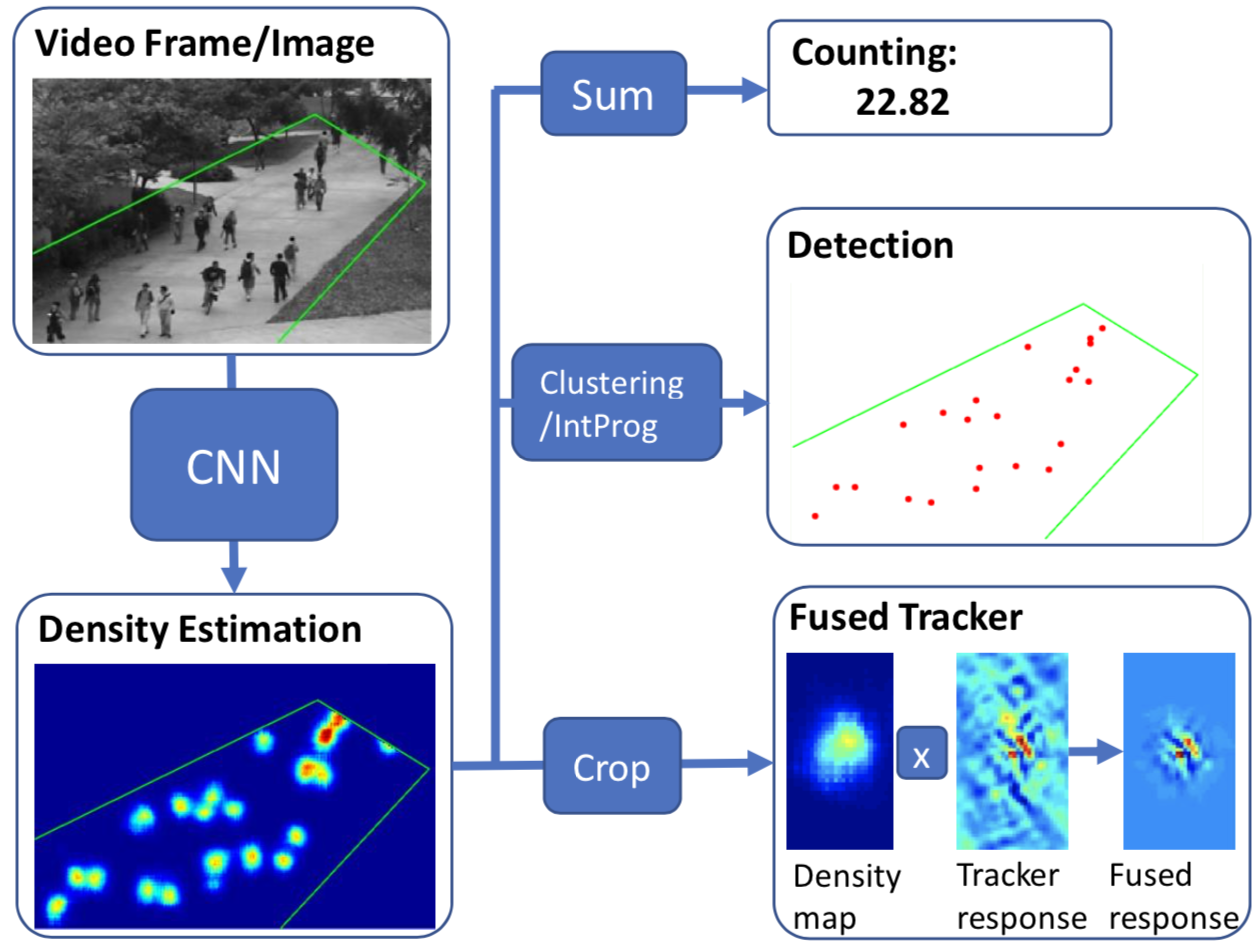
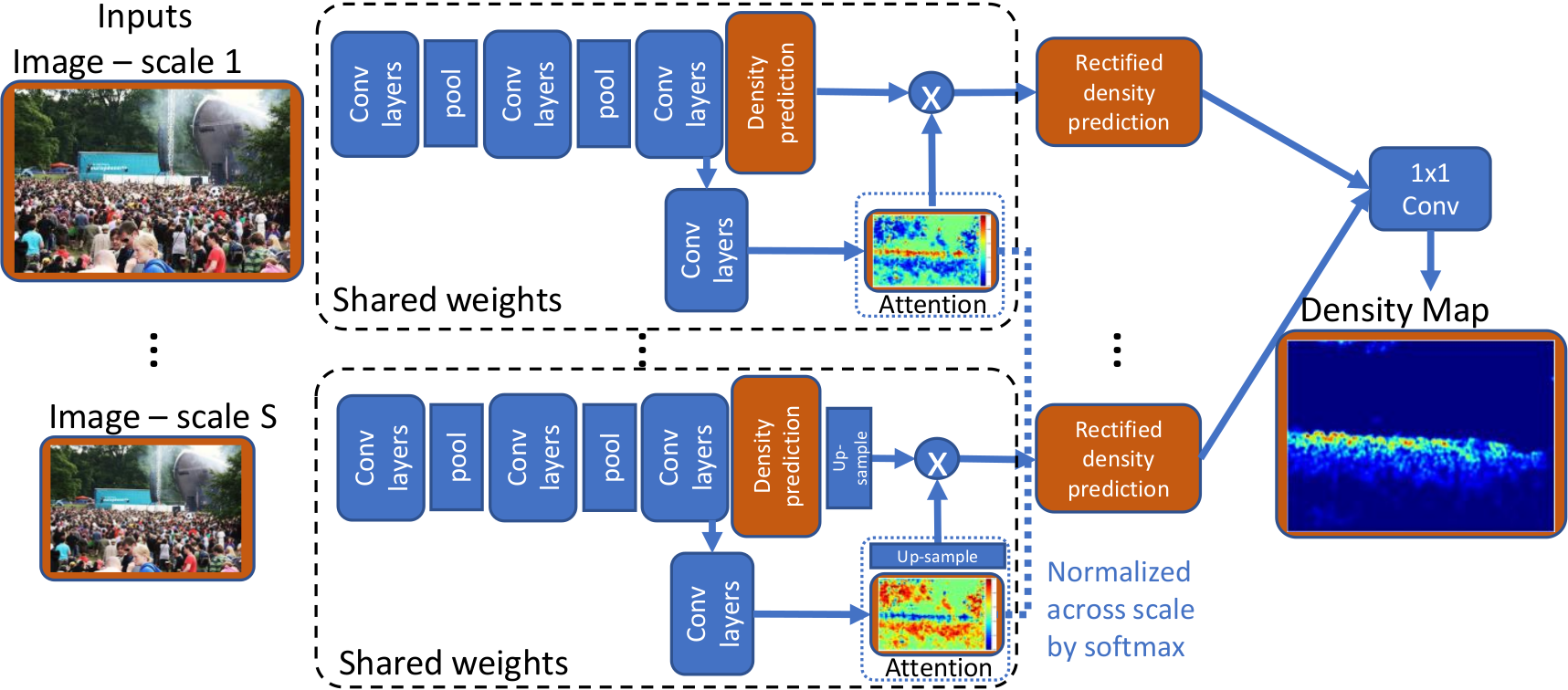
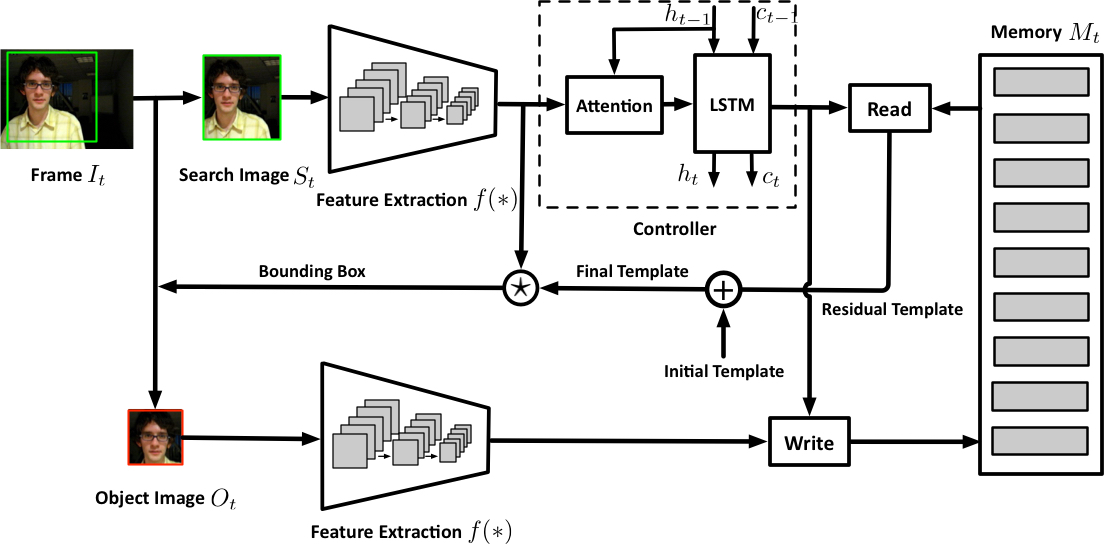
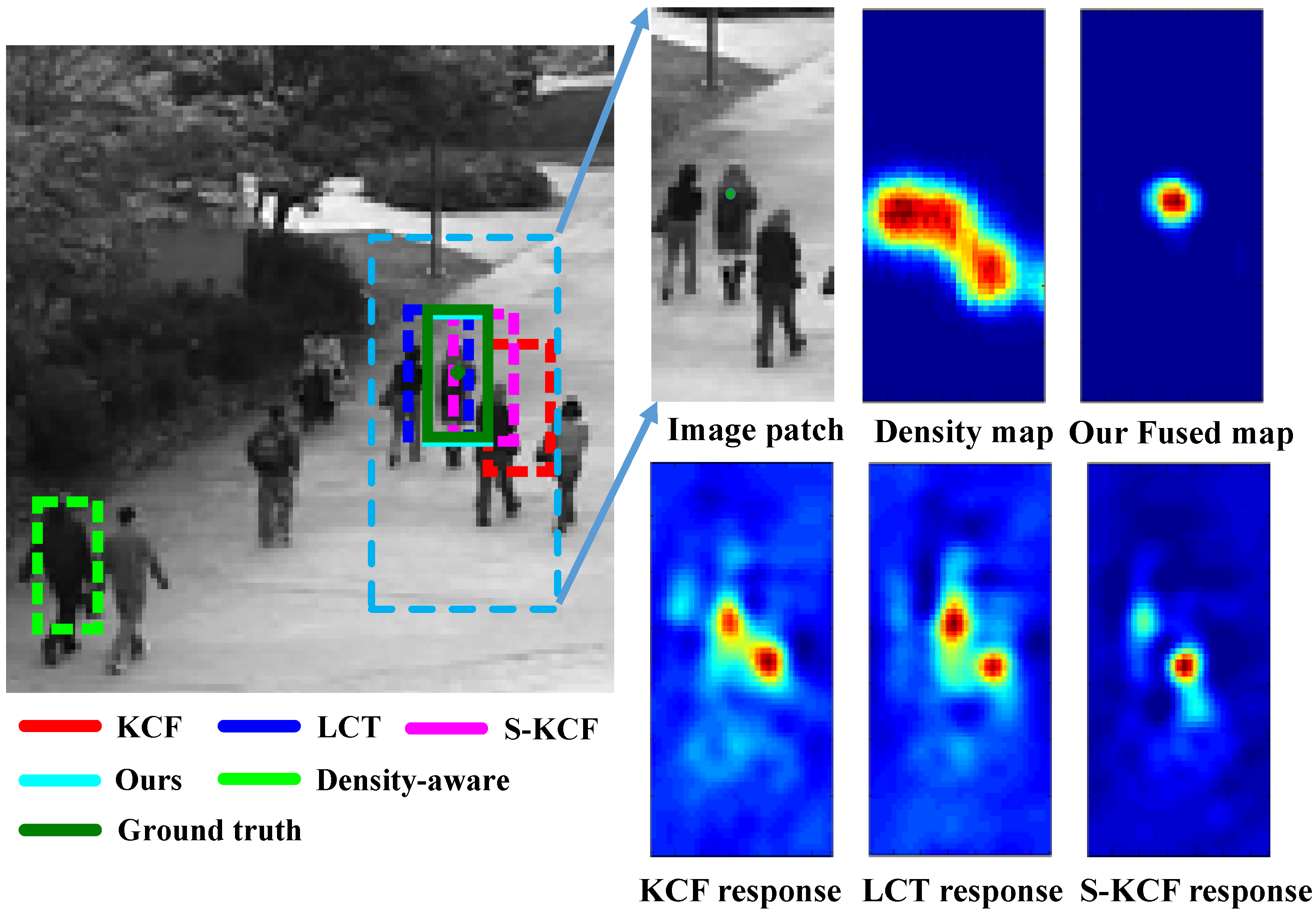
An algorithm is proposed to simplify the Gaussian Mixture Models into a reduced mixture model with fewer mixture components, by maximizing a variational lower bound of the expected log-likelihood of a set of virtual samples. RNN-based models dominate the field of image captioning, however, (1) RNNs have to be calculated step-by-step, which is not easily parallelized. (2) There is a long path between the start and end of the sentence using RNNs. Tree structures can make a shorter path, but trees require special processing. (3) RNNs only learn single-level representations at each time step, while convolutional decoders are able to learn multi-level representations of concepts, and each of them should corresponds to an image area, which should benefit word prediction. We propose CNN-pixel and FCNN-skip to produce an original-resolution density map. In our experiments, we found that the lower-resolution density maps sometimes have better counting performance. In contrast, the original-resolution density maps improved localization tasks, such as detection and tracking, compared to bilinear upsampling the lower-resolution density maps. We utilize an image pyramid to deal with scale variations. What’s more, we adaptively fuse the predictions from different scales (using adaptively changing per-pixel weights), which makes our method adapt to scale changes within an image. We propose a dynamic memory network to adapt the template to the target’s appearance variations during tracking where an LSTM is used to control the reading and writing process of the memory block. We propose a crowd people tracking framework that fuses the generic visual object tracker with an estimated crowd density map using a convolutional neural network (CNN). Also, we design a Sparse Kernelized Correlation Filter (S-KCF) to suppress target response variations caused by occlusions and illumination changes, and spurious responses.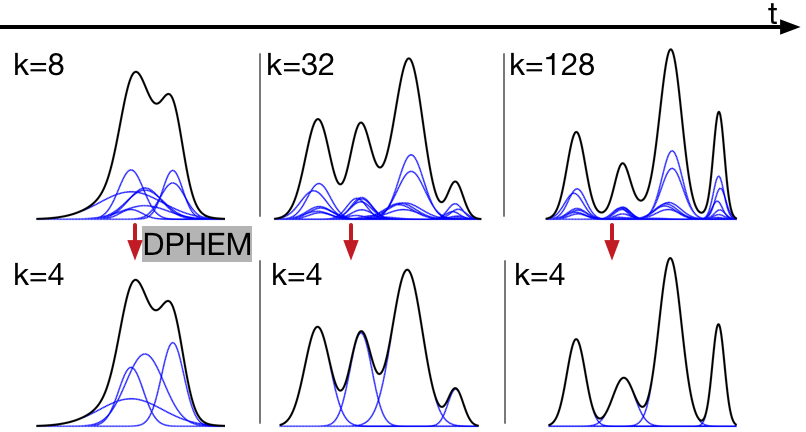
![]()
2017
In order to incorporate the available side information, we propose an adaptive convolutional neural network (ACNN), where the convolution filter weights adapt to the current scene context via the side information. We propose a recurrent filter generation methods for visual tracking which directly feeds the target’s image patch to a recurrent neural network (RNN) to estimate an object-specific filter for tracking. We propose a method for animating still manga imagery through camera movements, driven by motion and emotion semantics automatically extracted from the manga. We collect a multi-view and stereo-depth dataset for 3D human pose estimation, which consists of challenging martial arts actions (Tai-chi and Karate), dancing actions (hip-hop and jazz), and sports actions (basketball, volleyball, football, rugby, tennis and badminton).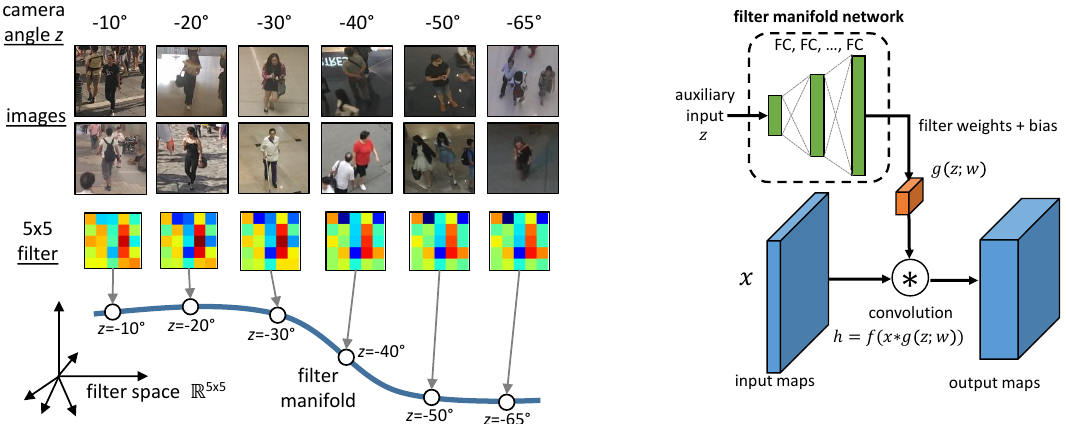
![]()

2016
We present an approach that allows web designers to easily direct user attention via visual flow on web designs.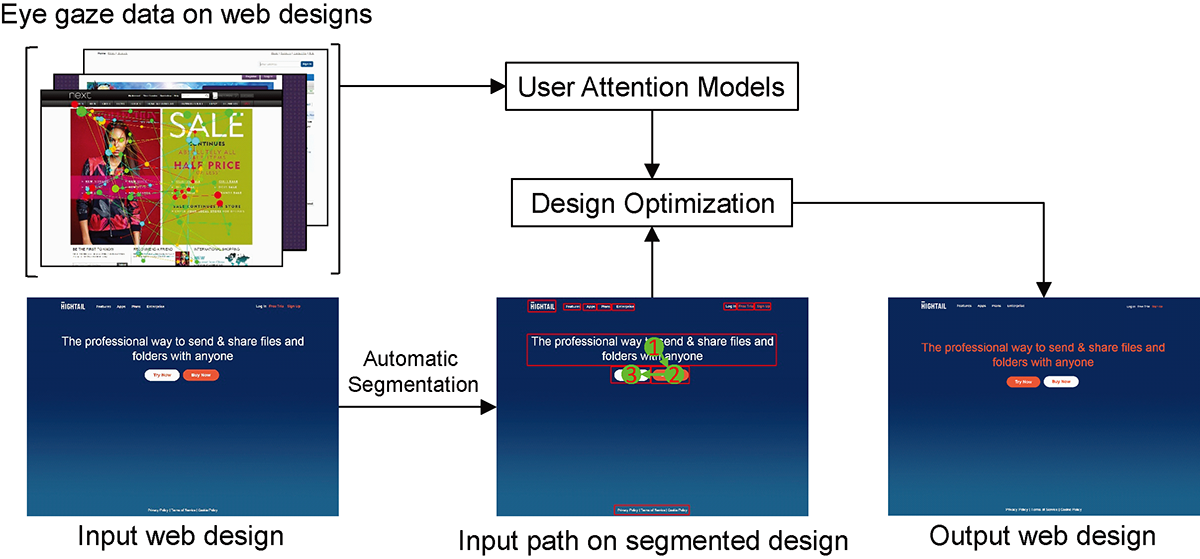
2015
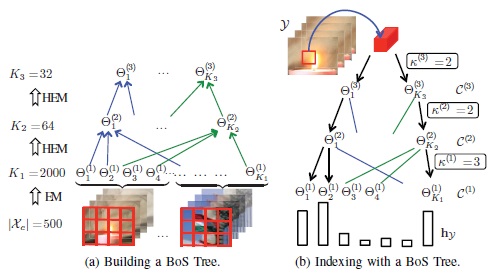
We propose a maximum-margin structured learning framework with deep neural network that learns the image-pose score function for human pose estimation. We propose a novel object detection framework using object density maps for partially-occluded small instances, such as pedestrians in low resolution surveillance video. We propose the BoSTree that enables efficient mapping of videos to the bag-of-systems (BoS) codebook using a tree-structure, which enables the practical use of larger, richer codebooks. 
2014
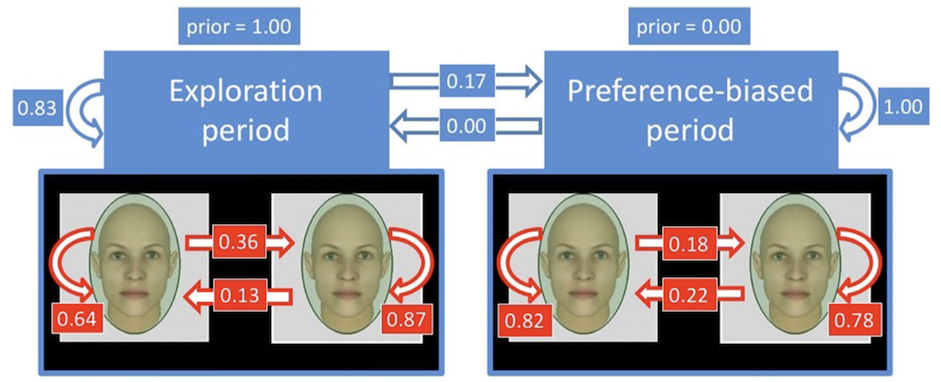
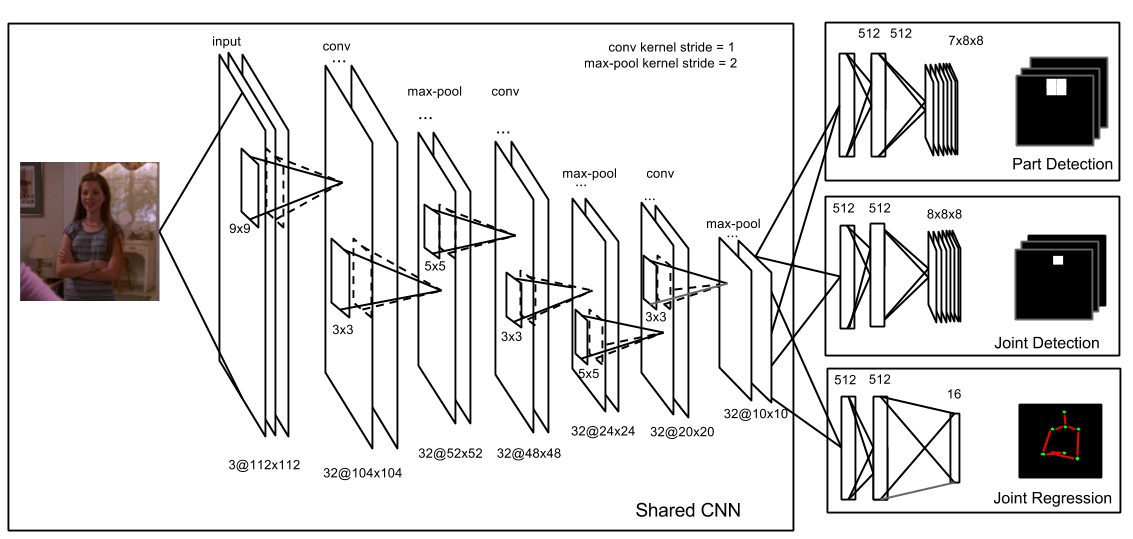
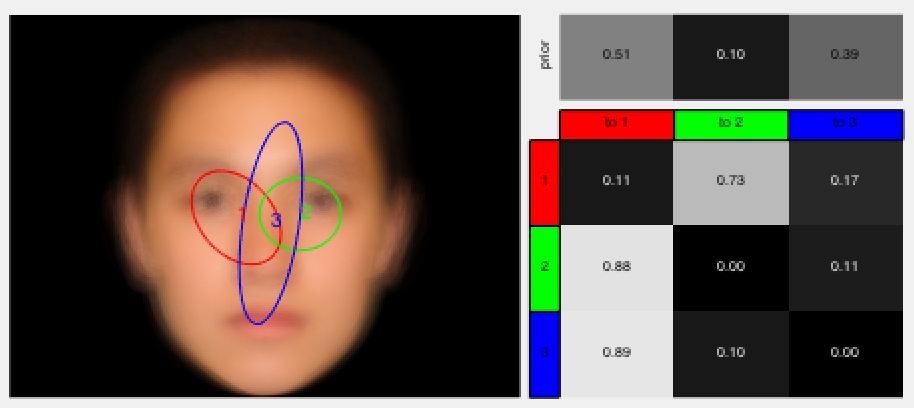
We propose a robust likelihood function for 3D human pose tracking, which is robust to small pose changes and better able to localize partially occluded and overlapping parts. We propose an approach for novices to synthesize a composition of panel elements that can effectively guide the reader’s attention to convey the story. We propose a heterogeneous multi-task learning framework for 2D human pose estimation from monocular images using a deep convolutional neural network that combines pose regression and part detection. We also extend the model to 3D human pose estimation. We use hidden Markov models (HMMs) to analyze eye movement data. A person’s eye fixation sequence is summarized with an HMM, and common strategies among people are discovered by clustering HMMs. We propose a variational hierarchical EM algorithm for clustering hidden Markov models (HMMs), producing groups of similar HMMs and their representative HMM cluster centers. We also propose a variational Bayesian version that performs model selection.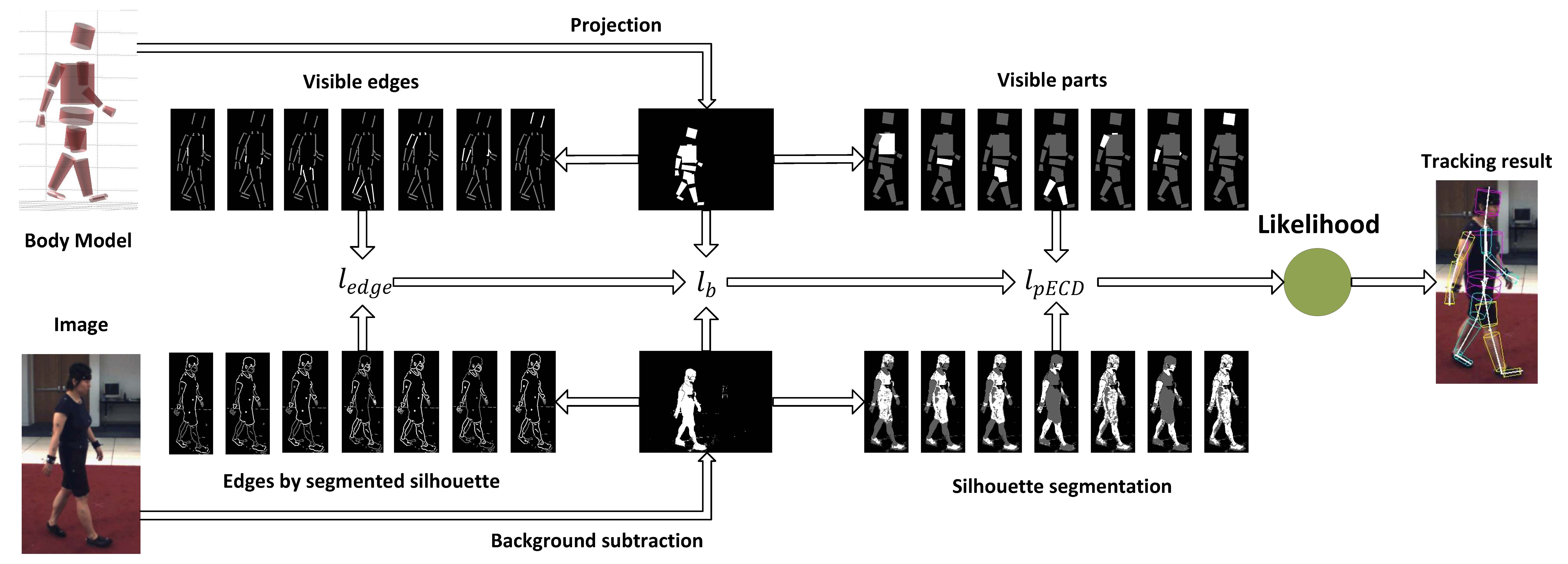
![]()
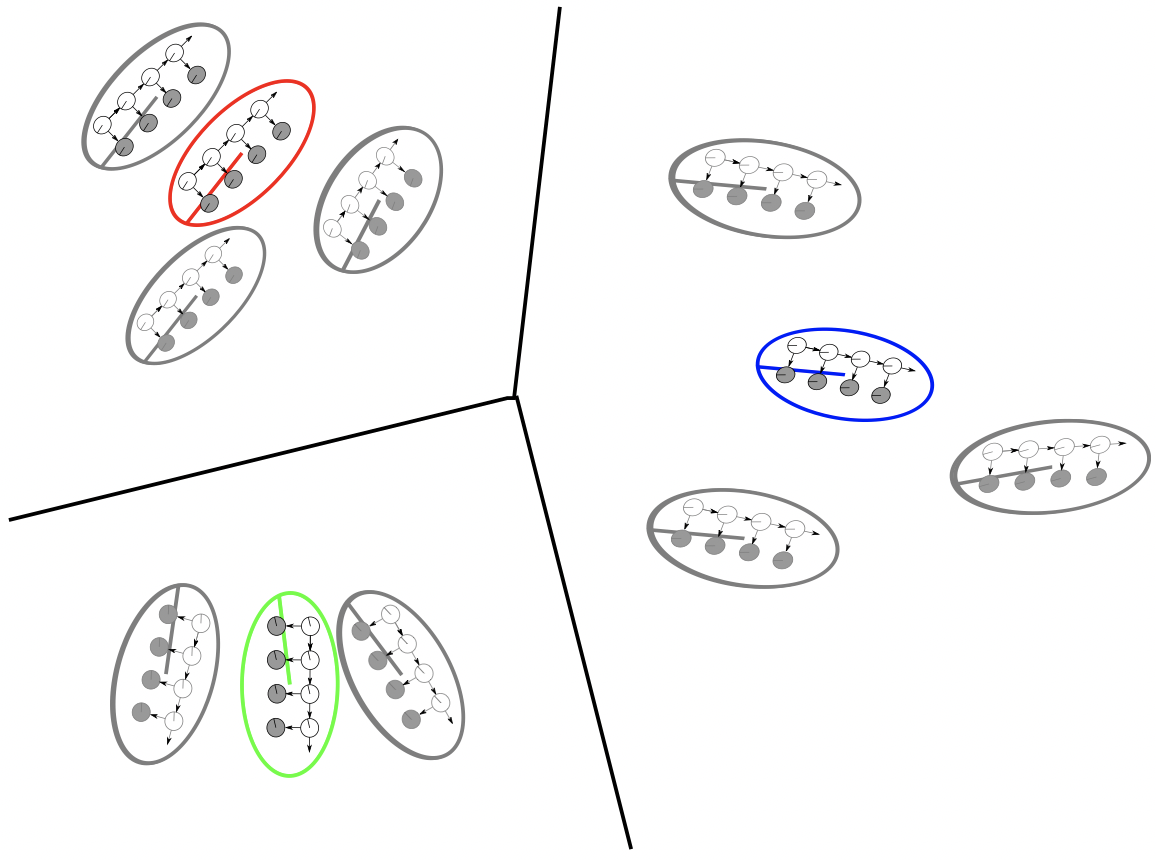
2013
We propose a hierarchical EM algorithm capable of clustering dynamic texture models and learning novel cluster centers that are representative of the cluster members. DT clustering can be applied to semantic motion annotation and bag-of-systems codebook generation. We propose an integer programming method for estimating the instantaneous count of pedestrians crossing a line of interest in a video sequence.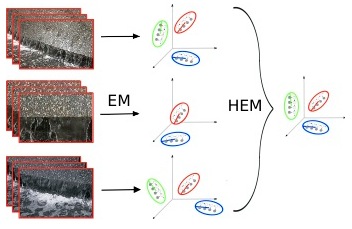

2012
We propose an approach to automatically produce a manga layout from a set of input artworks, which is based on a generative layout model and parametric style models. We estimate the size of moving crowds in a privacy preserving manner, i.e. without people models or tracking. The system first segments the crowd by its motion, extracts low-level features from each segment, and estimates the crowd count in each segment using a Gaussian process.
2011
We propose an approach to automatic music annotation and retrieval that is based on the dynamic texture mixture, a generative time series model of musical content. The new annotation model better captures temporal (e.g., rhythmical) aspects as well as timbral content. The background model is based on a generalization of the Stauffer-Grimson background model, where each mixture component is a dynamic texture. We derive an on-line algorithm for updating the parameters using a set of sufficient statistics of the model. 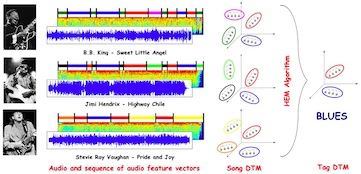
![]()
2010
We model a time-series of audio feature vectors, extracted from a short audio fragment, as a dynamic texture. The musical structure of a song (e.g. chorus, verse, and bridge) is discovered by segmenting the song using the mixture of dynamic textures. The song segmentations are used for song retrieval, song annotation, and database visualization.
2009
One disadvantage of the dynamic texture is its inability to account for multiple co-occuring textures in a single video. We extend the dynamic texture to a multi-state (layered) dynamic texture that can learn regions containing different dynamic textures.
2008
We introduce the mixture of dynamic textures, which models a collection of video as samples from a set of dynamic textures. We use the model for video clustering and motion segmentation.
2007
We annotate images using supervised multi-class labeling (SML), which treats semantic annotation as a multi-class classification problem. The system is scalable, and was applied to image databases with 60,000 images. We introduce a kernelized dynamic texture, which has a non-linear observation function learned with kernel PCA. The new texture model can account for more complex patterns of motion, such as chaotic motion (e.g. boiling water and fire) and camera motion (e.g. panning and zooming), better than the original dynamic texture. 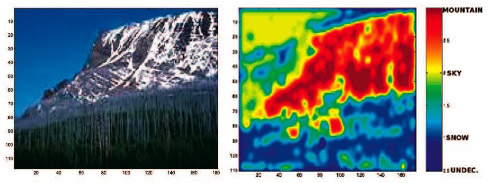
2005
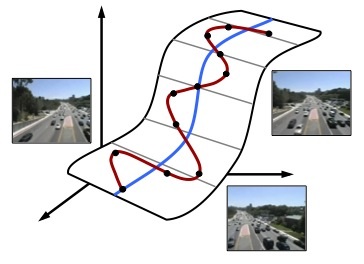
We classify traffic congestion in video by representing the video as a dynamic texture, and classifying it using an SVM with a probabilistic kernel (the KL kernel). The resulting classifier is robust to noise and lighting changes.