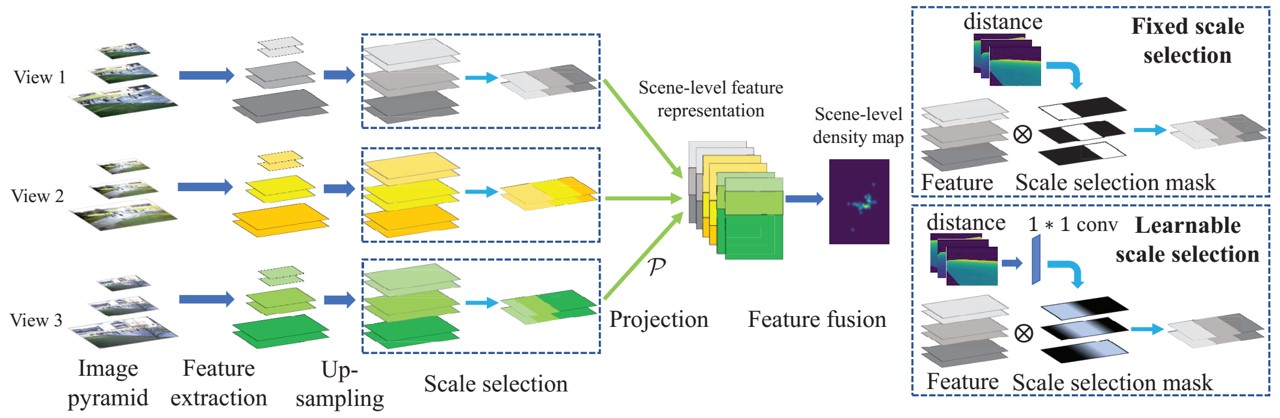
Crowd counting in single-view images has achieved outstanding performance on existing counting datasets. However, single-view counting is not applicable to large and wide scenes (e.g., public parks, long subway platforms, or event spaces) because a single camera cannot capture the whole scene in adequate detail for counting, e.g., when the scene is too large to fit into the field-of-view of the camera, too long so that the resolution is too low on faraway crowds, or when there are too many large objects that occlude large portions of the crowd. Therefore, to solve the wide-area counting task requires multiple cameras with overlapping fields-of-view. In this paper, we propose a deep neural network framework for multi-view crowd counting, which fuses information from multiple camera views to predict a scene-level density map on the ground-plane of the 3D world. We consider 3 versions of the fusion framework: the late fusion model fuses camera-view density maps; the na¨ıve early fusion model fuses camera-view feature maps; and the multi-view multi-scale early fusion model favors that features aligned to the same ground-plane point have consistent scales. We test our 3 fusion models on 3 multi-view counting datasets, PETS2009, DukeMTMC, and a newly collected multi-view counting dataset containing a crowded street intersection. Our methods achieve state-of-the-art results compared to other multi-view counting baselines.
Selected Publications
,
International Journal of Computer Vision (IJCV), 130(8):1938-1960, Aug 2022. [github]
,
In: IEEE/CVF Conf. on Computer Vision and Pattern Recognition (CVPR), Long Beach, June 2019. [dataset&code | github]
Datasets
Results
Code:
Cite our papers:
- @inproceedings{zhang2019wide,
title={Wide-Area Crowd Counting via Ground-Plane Density Maps and Multi-View Fusion CNNs},
author={Zhang, Qi and Chan, Antoni B},
booktitle={Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition},
pages={8297–8306},
year={2019}
} - @inproceedings{zhang2020wide,
title={Wide-Area Crowd Counting: Multi-View Fusion Networks for Counting in Large Scenes},
author={Zhang, Qi and Chan, Antoni B},
booktitle={International Journal of Computer Vision, 10.1007/s11263-022-01626-4},
pages={1938-1960}
year={2022}
}