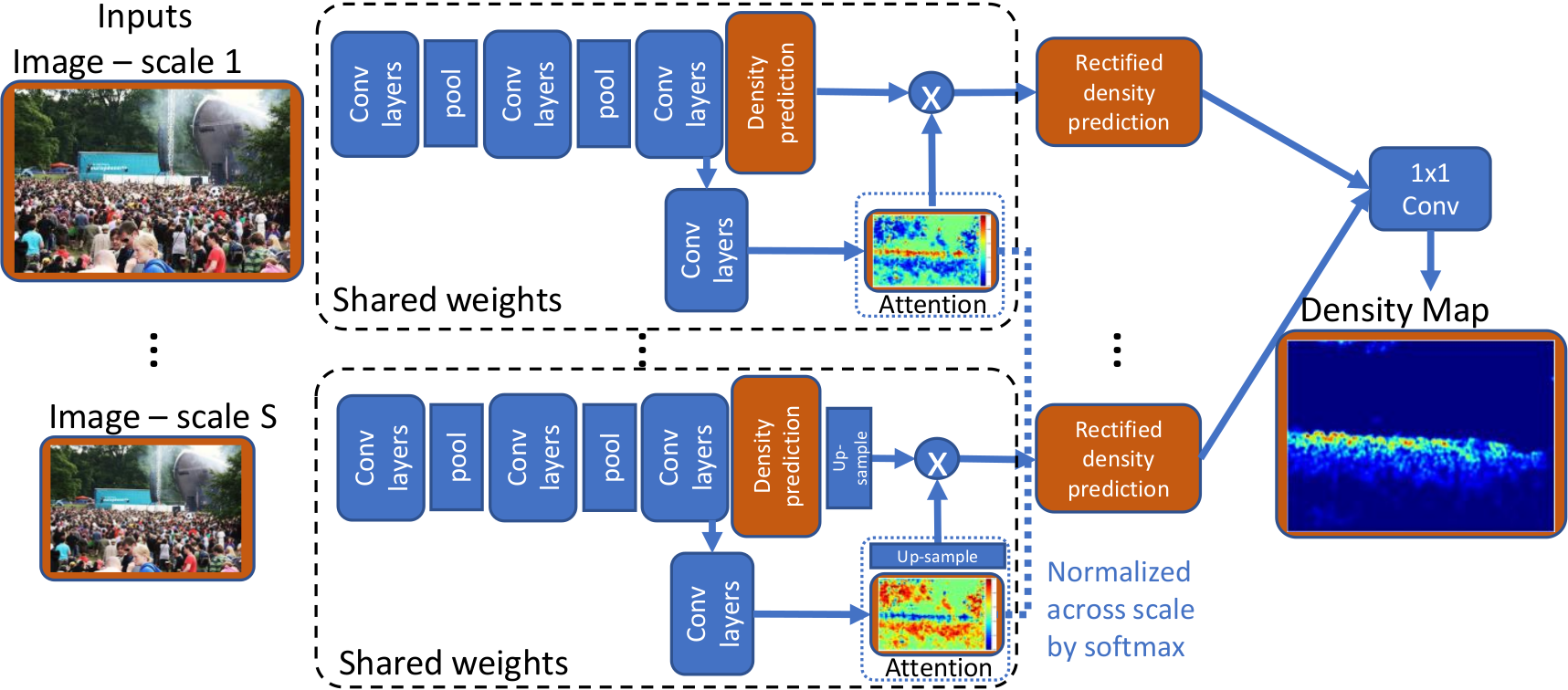
Because of the powerful learning capability of deep neural networks, counting performance via density map estimation has improved significantly during the past several years. However, it is still very challenging due to severe occlusion, large scale variations, and perspective distortion. Scale variations (from image to image) coupled with perspective distortion (within one image) result in huge scale changes of the object size. Earlier methods based on convolutional neural networks (CNN) typically did not handle this scale variation explicitly, until Hydra-CNN and MCNN. MCNN uses three columns, each with different filter sizes, to extract features at different scales. In this paper, in contrast to using filters of different sizes, we utilize an image pyramid to deal with scale variations. It is more effective and efficient to resize the input fed into the network, as compared to using larger filter sizes. Secondly, we adaptively fuse the predictions from different scales (using adaptively changing per-pixel weights), which makes our method adapt to scale changes within an image. The adaptive fusing is achieved by generating an across-scale attention map, which softly selects a suitable scale for each pixel, followed by a 1×1 convolution. Extensive experiments on three popular datasets show very compelling results.
Selected Publications
- Crowd Counting by Adaptively Fusing Predictions from an Image Pyramid.
,
In: British Machine Vision Conference (BMVC), Newcastle, Sept 2018. [supplemental]