Motivation
- An image may contain many concepts with multiple levels of detail — indeed, an image is worth a thousand words — and thus an image caption expresses a set of concepts that are interesting for a particular human. Hence, there is diversity among captions due to diversity among humans, and an automatic image captioning method should reflect this.
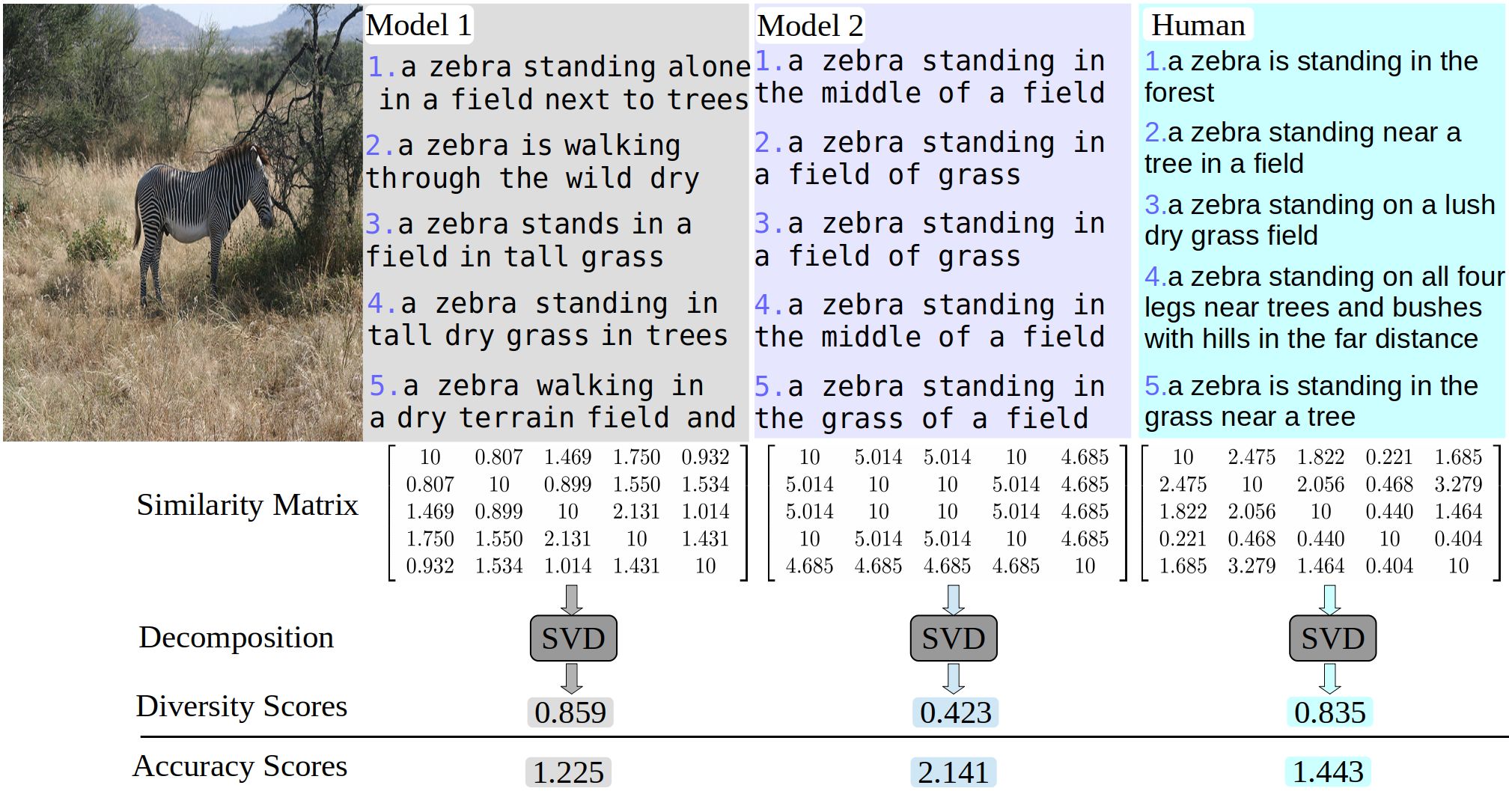
- Only focusing on increasing the caption accuracy will bias the captioning method to common phrases (see above figure).
- From the machine learning viewpoint, captioning models are typically trained on datasets where each image has at least 5 ground-truth captions (e.g., MSCOCO), and thus captioning models should also be evaluated on how well the learned conditional distribution of captions given an image approximates that of the ground-truth. In particular, while the caption accuracy measures the differences in the modes of the distributions, the caption diversity measures the variance of the distribution.
Diversity
- Word diversity refers to only changes of single words that do not change the caption’s semantics, e.g., using synonyms in different captions.
- Syntactic diversity refers to only differences in the word order, phrases, and sentence structures, such as pre-modification, post-modification, redundant and concise descriptions, which do not change the caption’s concept.
- Semantic diversity refers to the differences of expressed concepts, including the level of descriptive detail, changing of the sentence’s subject, and addition/removal of sentence objects.
Metrics

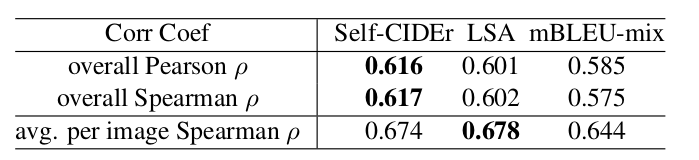
We also conduct human evaluations and our proposed metrics show a relatively high correlation to human judgment.
Re-evaluating the Existing Models
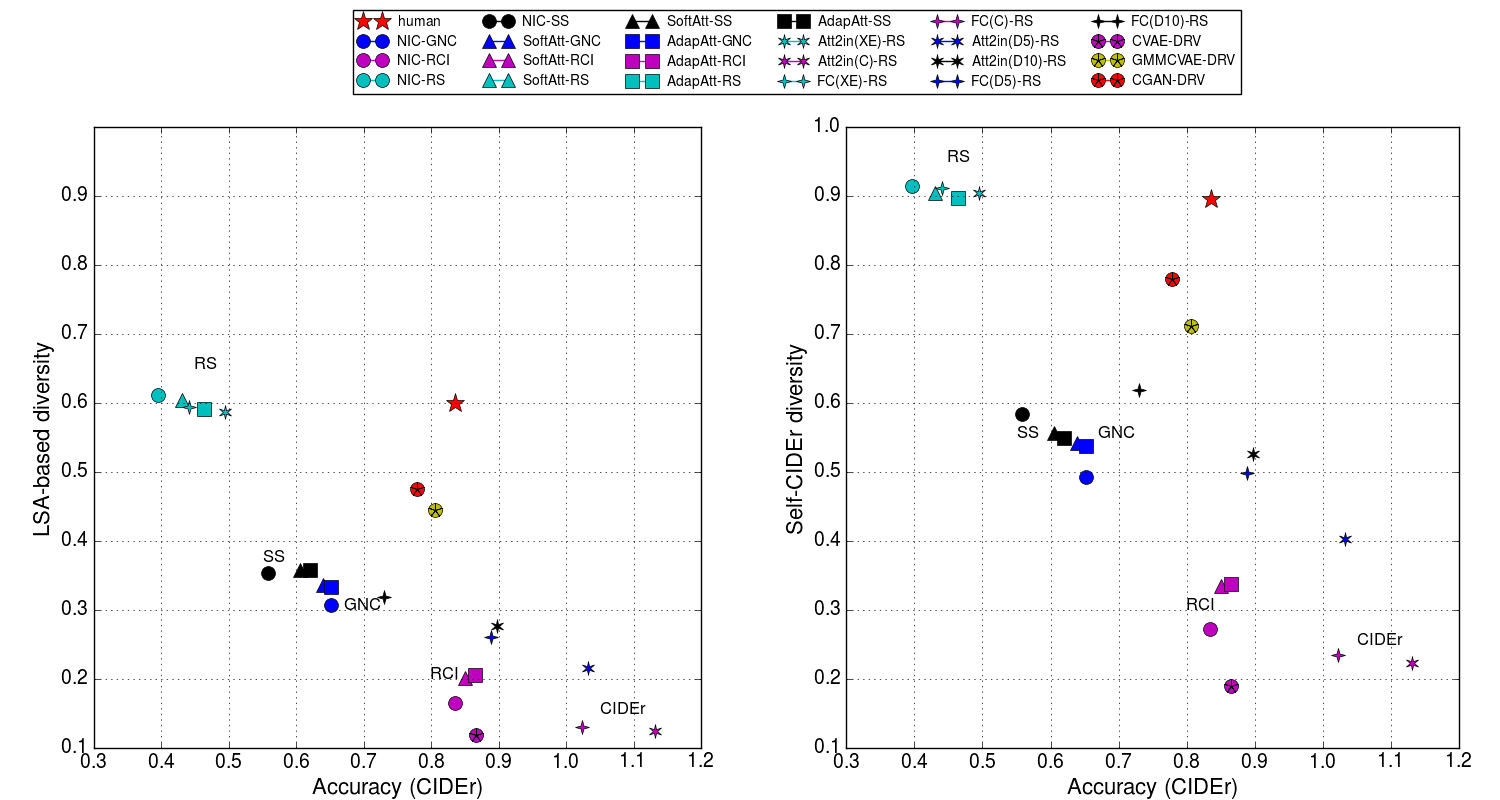
- There is a large gap between human annotations and the existing models.
- GAN and VAE models that are specific to diverse image captioning perform better.
- Using reinforcement learning (CIDEr reward) can significantly improve accuracy but reduce the diversity score.
- There is a large gap between using cross-entropy loss and reinforcement learning, which can be bridged via the linear combination of the two loss functions (see the following part).
Re-thinking Reinforcement Learning
As we mentioned, reinforcement learning method is able to generate diverse image captions using different loss functions.
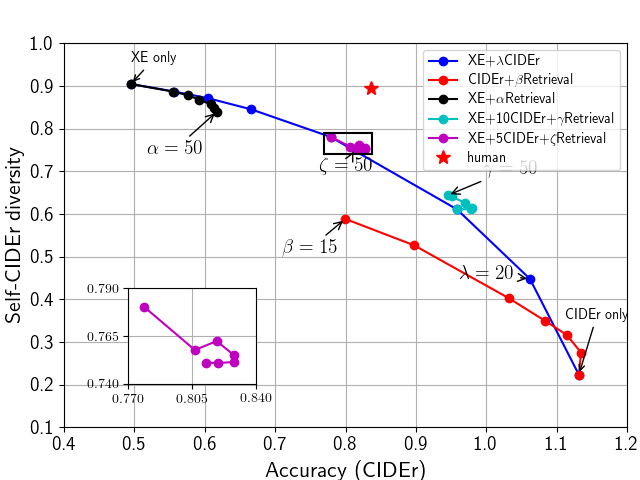
- Combining cross-entropy loss and CIDEr reward is the most efficient way to balance diversity and accuracy.
- Combining retrieval reward and CIDEr reward is able to improve diversity but could result in the repetition problem (repeat a word several times).
Publication
On Diversity in Image Captioning: Metrics and Methods.
,
IEEE Trans. on Pattern Analysis and Machine Intelligence (TPAMI), 44(2):1035-1049, Feb 2022. [github] Describing like Humans: on Diversity in Image Captioning.
,
In: IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , Long Beach, June 2019. [github]