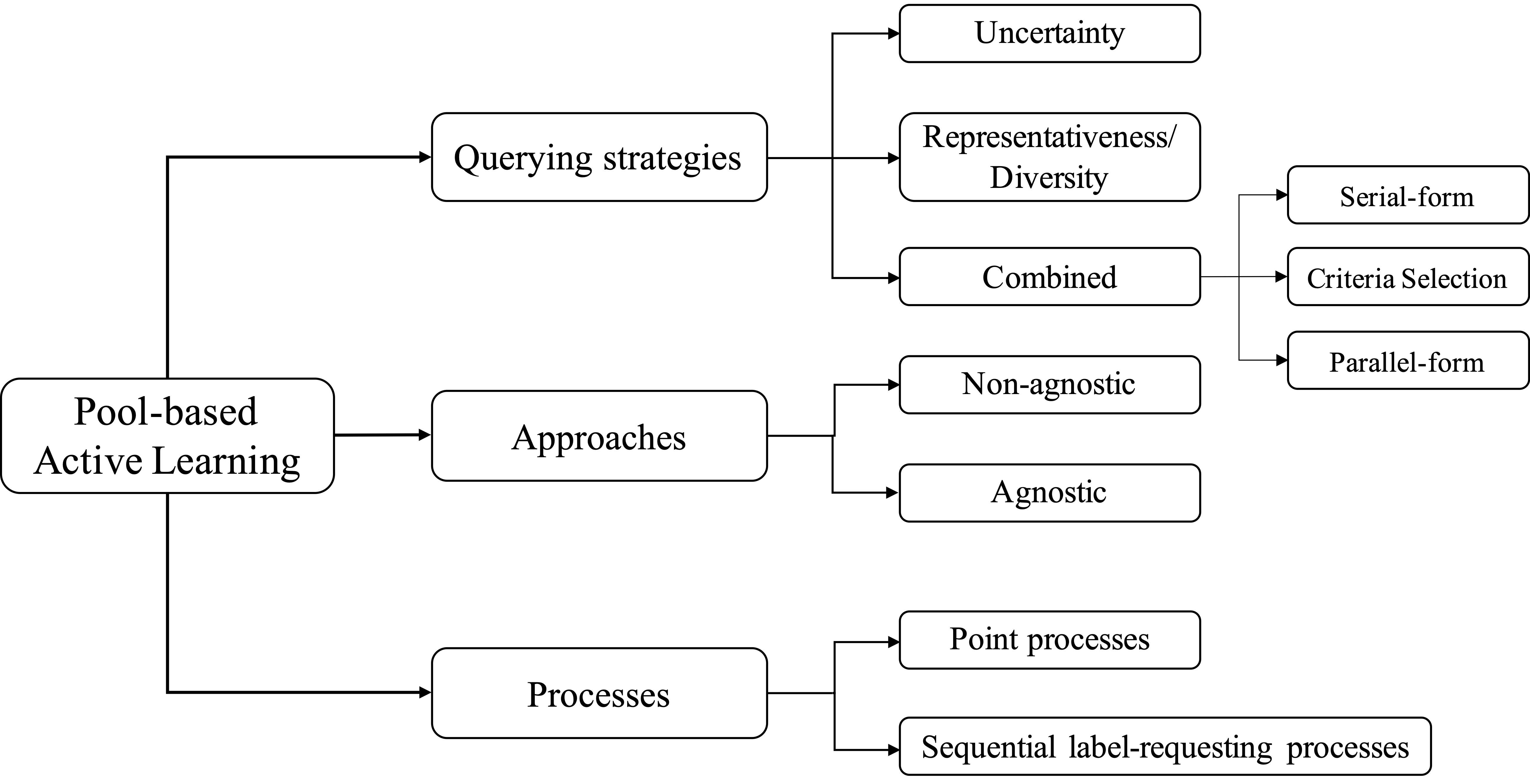
Active learning (AL) is a subfield of machine learning (ML) in which a learning algorithm aims to achieve good accuracy with fewer training samples by interactively querying the oracles to label new data points. Pool-based AL is well-motivated in many ML tasks, where unlabeled data is abundant, but their labels are hard or costly to obtain.
Although many pool-based AL methods have been developed, some important questions remain unanswered such as how to: 1) determine the current state-of-the-art technique; 2) evaluate the relative benefit of new methods for various properties of the dataset; 3) understand what specific problems merit greater attention; and 4) measure the progress of the field over time. We survey and compare various AL strategies used in both recently proposed and classic highly-cited methods. We propose to benchmark pool-based AL methods with a variety of datasets and quantitative metric, and draw insights from the comparative empirical results.
Pool-based AL approaches can be roughly classified into three categories:
- Uncertainty-based sampling strategies aim to select the unlabeled data samples with lowest confidence (largest uncertainty) for the model to be classified correctly, such as least confidence, margin/ratio of confidence, or entropy-based.
- Diversity/representative sampling strategies select data that contains diversity information of the data pool to reduce the constraints on the supervised machine learning models from data. e.g., outlier detection, cluster-based sampling , representative/density-based sampling.
- Combined strategies integrate the advantages of uncertainty-based and diversity-based criteria, and are widely adopted in AL and its applications since they are more adaptable to varying data types.
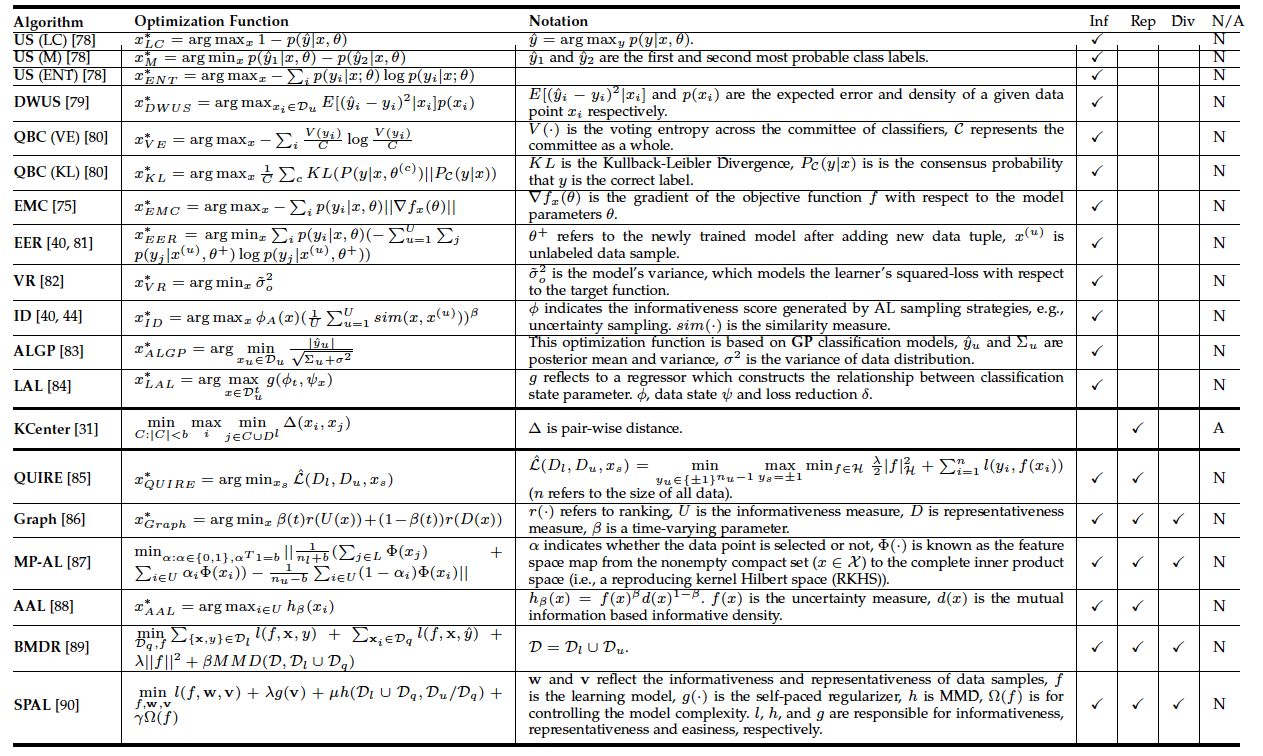
We summarize various Active Learning algorithms, including their sampling strategies and objective functions:
Results
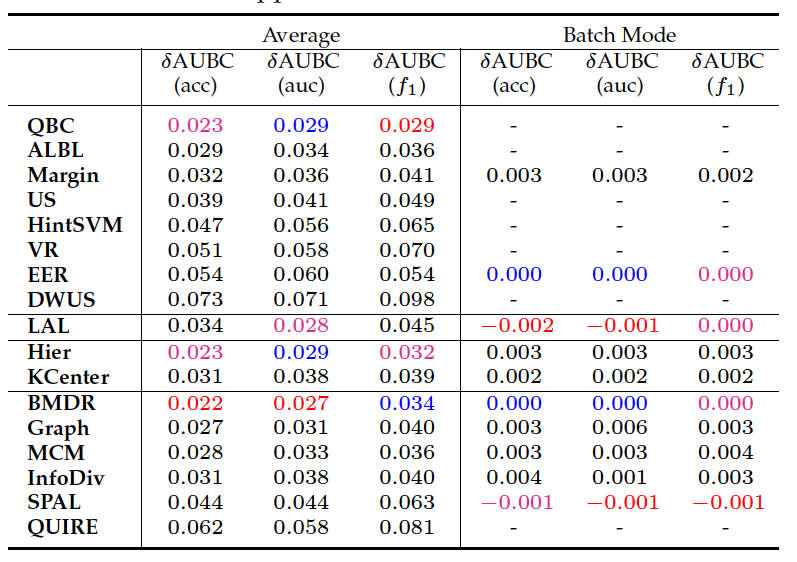
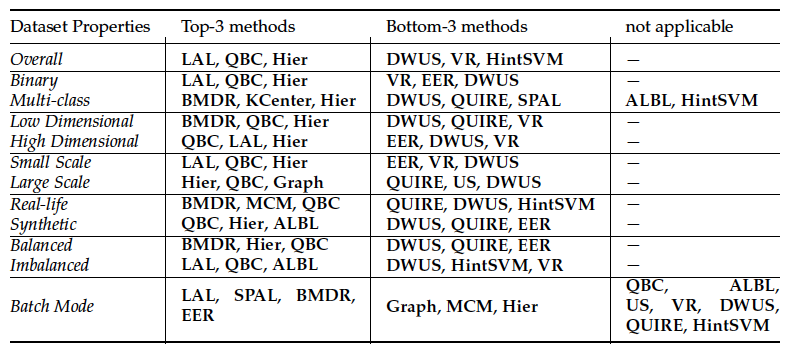
We tested 17 AL methods across 35 public datasets (classical machine learning tasks) and report the average performance and from different aspects.
- Average:
- Performance on different aspects of the data:
Publications
- A Comparative Survey: Benchmarking for Pool-based Active Learning.
,
In: International Joint Conf. on Artificial Intelligence (IJCAI), Survey Track, Aug 2021. [github]
Code/Data
- Code and data is available here.