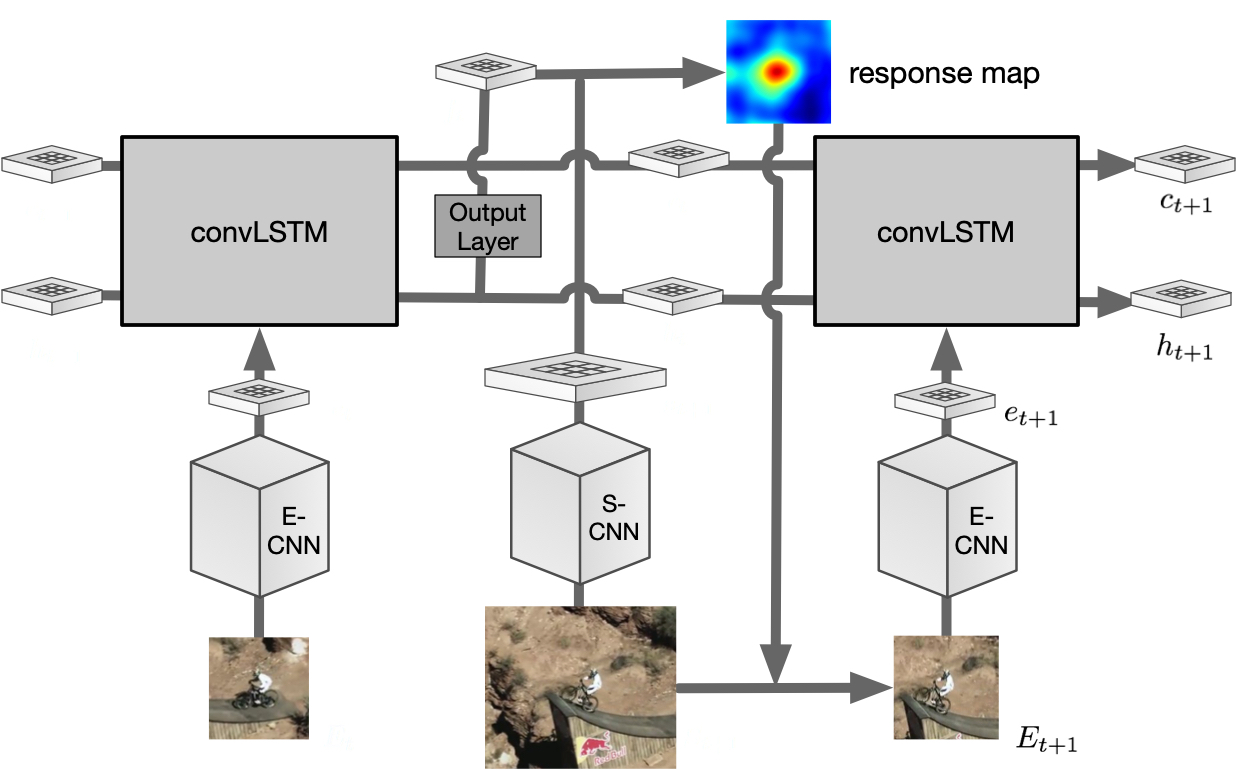
Recently using convolutional neural networks (CNNs) has gained popularity in visual tracking, due to its robust feature representation of images. Recent methods perform online tracking by fine-tuning a pre-trained CNN model to the specific target object using stochastic gradient descent (SGD) back-propagation, which is usually time-consuming. In this paper, we propose a recurrent filter generation methods for visual tracking. We directly feed the target’s image patch to a recurrent neural network (RNN) to estimate an object-specific filter for tracking. As the video sequence is a spatiotemporal data, we extend the matrix multiplications of the fully-connected layers of the RNN to a convolution operation on feature maps, which preserves the target’s spatial structure and also is memory-efficient. The tracked object in the subsequent frames will be fed into the RNN to adapt the generated filters to appearance variations of the target. Note that once the off-line training process of our network is finished, there is no need to fine-tune the network for specific objects, which makes our approach more efficient than methods that use iterative fine-tuning to online learn the target. Extensive experiments conducted on widely used benchmarks, OTB and VOT, demonstrate encouraging results compared to other recent methods.
Publications
- Recurrent filter learning for visual tracking.
,
In: ICCV 5th Visual Object Tracking Challenge Workshop VOT2017, Venice, Oct 2017. [video | github]