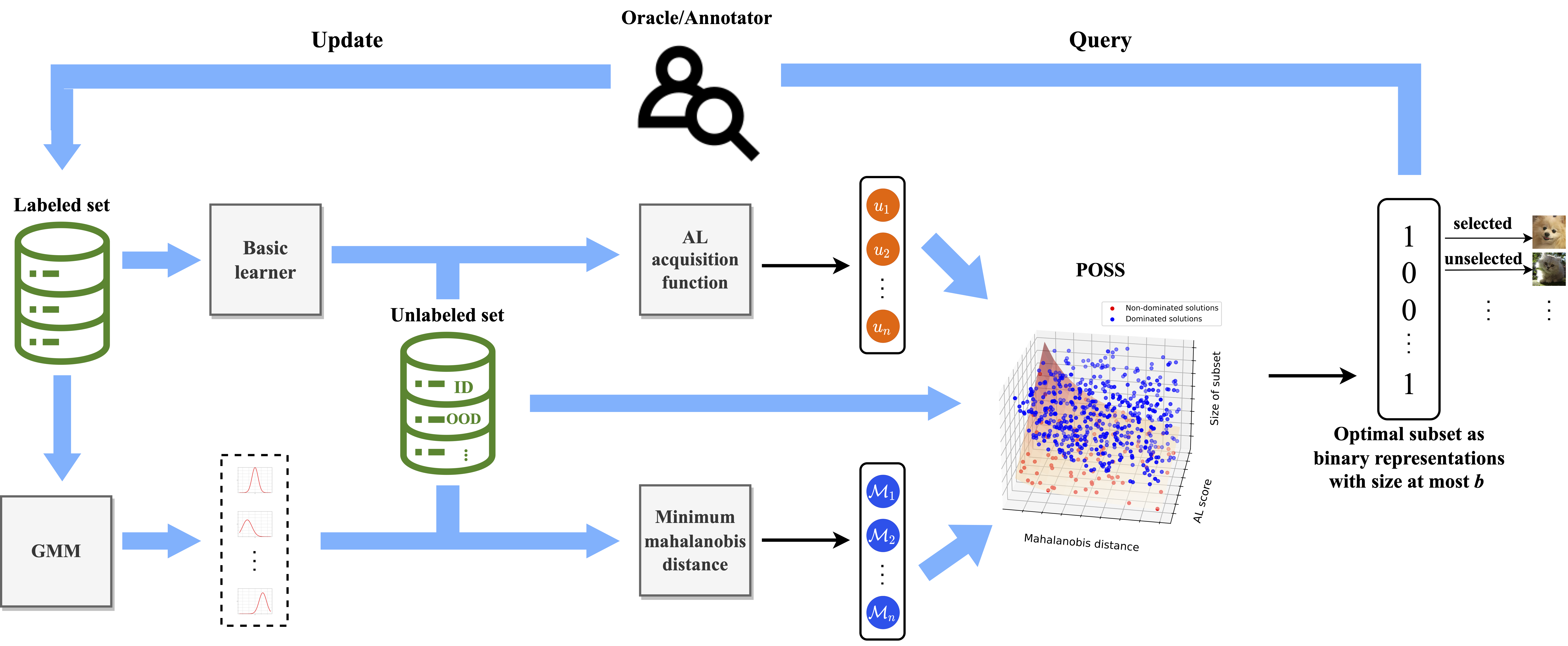
We propose a novel and flexible batch-mode Pareto Optimization Active Learning (POAL) framework for Active Learning under Out-of-Distribution data scenarios. Most existing AL sampling schemes are designed under clean datasets, do not perform well in out-of-distribution (OOD) data scenarios, where the unlabeled data pool contains samples that do not belong to the pre-defined categories of the target task. To solve this issue, we advocate simultaneously considering the AL criterion and In-/Out-of-Distribution confidence score calculation when designing AL sampling strategies, aims to improve AL when encountering OOD data in the unlabeled data pool. There is a natural conflict between AL sampling process and OOD data detection, so we propose AL under OOD data scenarios within a multi-objective optimization framework. POAL is flexible and can accommodate different combinations of AL and OOD detection methods according to various target tasks. In this work, we use the class-conditional probabilities as the AL objective and Mahalanobis distance as ID/OOD confidence scores.
Our contributions are as follows:
- Naively applying Pareto optimization to AL will result in a Pareto Front with a non-fixed size, which can introduce high computational costs. To enable efficient Pareto optimization, we propose a Monte- Carlo (MC) Pareto optimization algorithm for fixed-size batch-mode AL. We change the search space from data point level to subset level. Compared with typical Pareto Optimization of data point level, MCPOAL achieve better performance by selecting near-optimal subset with less OOD data samples.
- POAL works well on classical Machine Learning and Deep Learning tasks. We propose pre-selecting and early-stopping techniques to reduce the computational cost of large-scale datasets.
- POAL has no trade-off hyper-parameter for balancing AL and OOD objectives. It is crucial since i) AL is data-insufficient, there might be no validation set for tuning parameters; ii) hyper-parameter tuning in AL can be label-expensive since every change of hyper-parameter causes AL to label new data, thus provoking substantial labeling inefficiency.
Publications
- Pareto Optimization for Active Learning under Out-of-Distribution Data Scenarios.
,
Transactions on Machine Learning Research (TMLR), June 2023. [github]