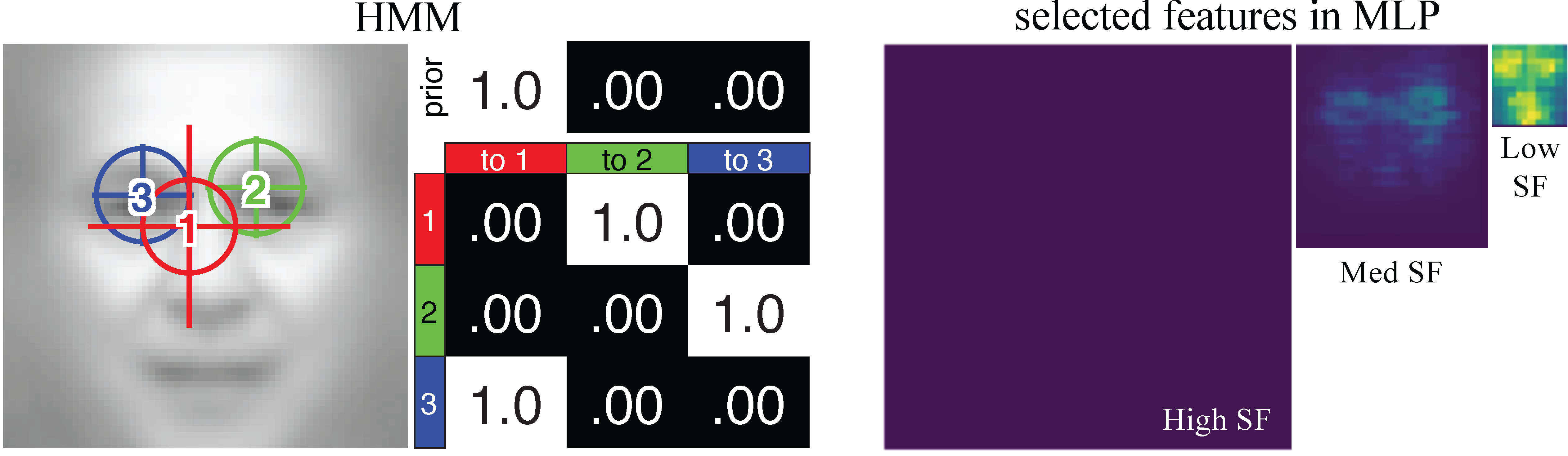
We propose a novel computational model that combines a DNN and a hidden Markov model (HMM) to learn eye movement strategies including both sequences of eye fixation locations and associated attention window sizes (global/local attention) for recognition. This DNN+HMM model integrates perceptual representation and eye movement pattern learning: The DNN learns optimal perceptual representations under the guidance of an attention mechanism summarised in an HMM, and the HMM learns optimal eye movement strategies through feedback from the DNN. In contrast to previous approaches where the attended location of the DNN can be anywhere in the stimulus without an interpretable model for a person’s strategy, here we assume that fixations occur within person-specific regions of interest (ROIs) to reflect the idiosyncratic eye movement behaviour during recognition. We also include constraints of human perception, such as saccade noise and visual-spatial acuity of the retina, into our DNN+HMM model. Here is the overall architecture of the DNN+HMM.
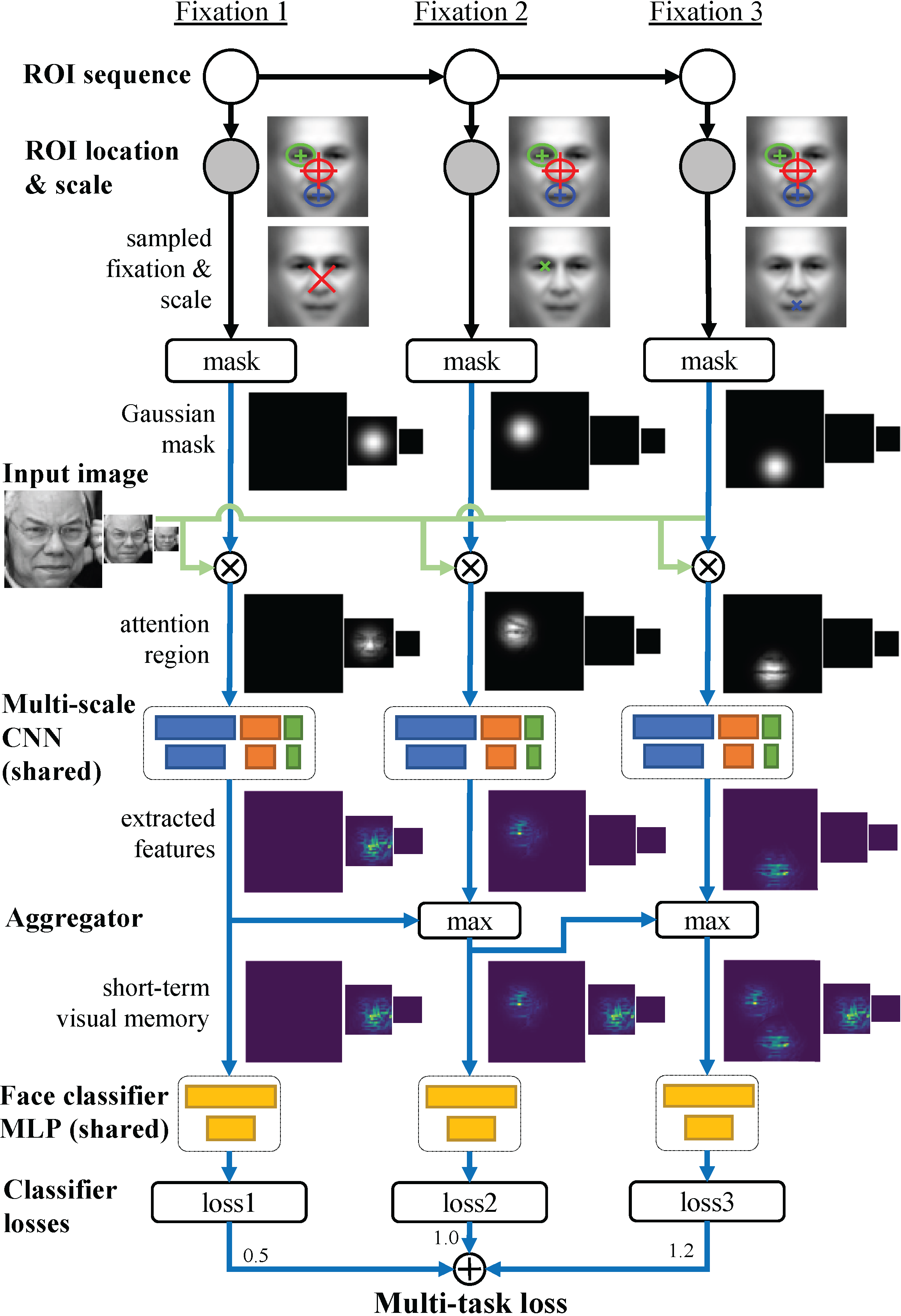
An example individual trained on a face recognition task is shown at the top of the page.
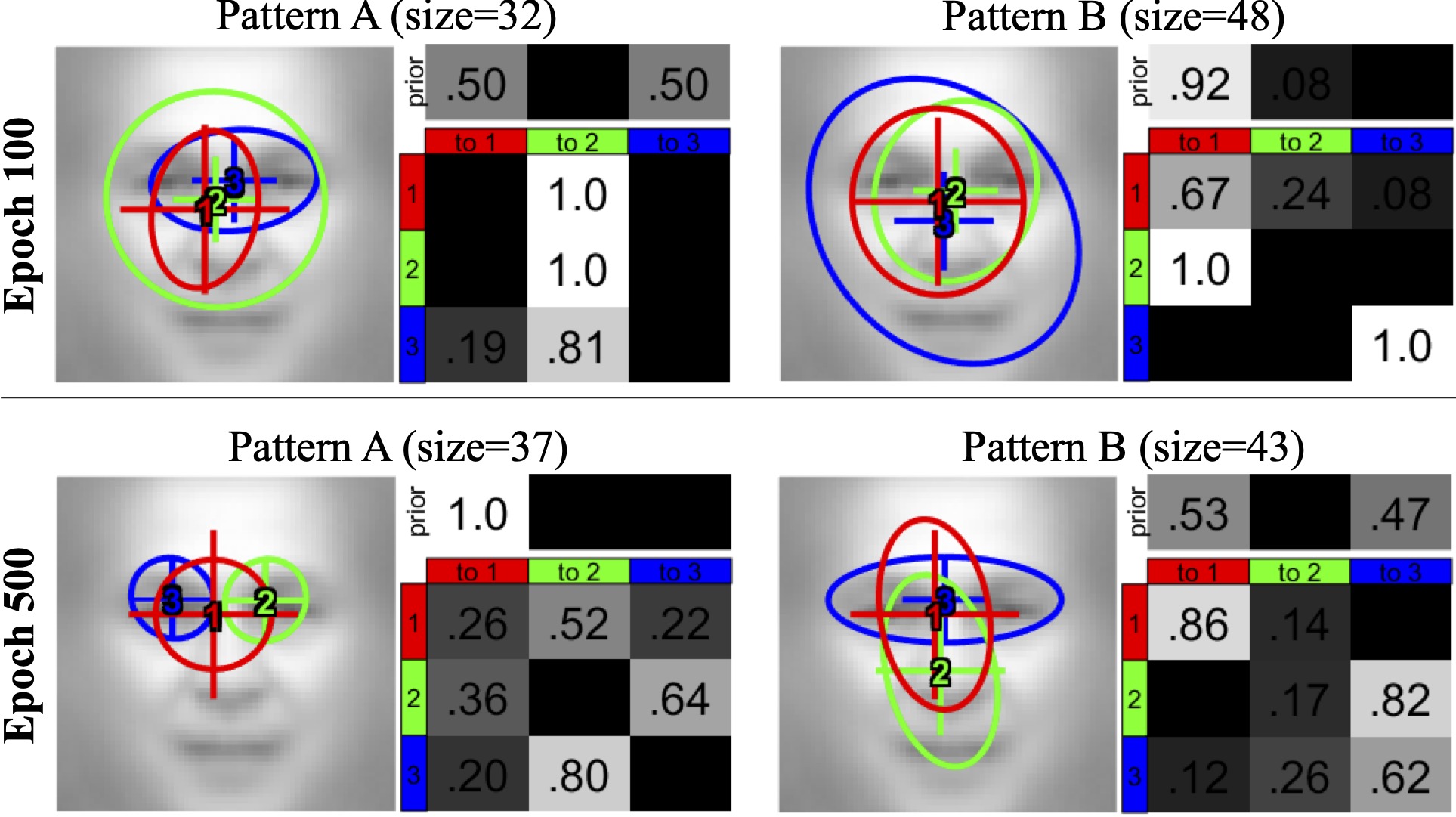
We trained the DNN+HMM on the aligned Labeled Faces in the Wild (LFW-a) dataset for 80 times from random initializations to simulate 80 individuals. We applied clustering with EMHMM to obtain two representative patterns for well-trained (adult) models at epoch 500, and two representative patterns for partially trained (child) models at epoch 100 (Fig. 4a). The well-trained models exhibited an eyes-focused (pattern A) and a nose-focused eye movement pattern (pattern B), and the partially trained models exhibited similar representative eye movement patterns.
In the well-trained models, those with pattern A (eye-focused) exhibited higher accuracy than pattern B (nose-focused), and accuracy was positively correlated with AB scale. In contrast, the patterns A and B of partially trained models did not differ in accuracy on the validation data, and the AB scale was not correlated with accuracy. Thus, eye movement pattern was correlated with accuracy in well-trained models, but not partially trained models. Finally, we examined eye movement consistency. The entropy of partially trained models was negatively correlated with accuracy. In contrast, well-trained models did not show a correlation between entropy and accuracy, as most well-trained models have converged to consistent, low entropy patterns.
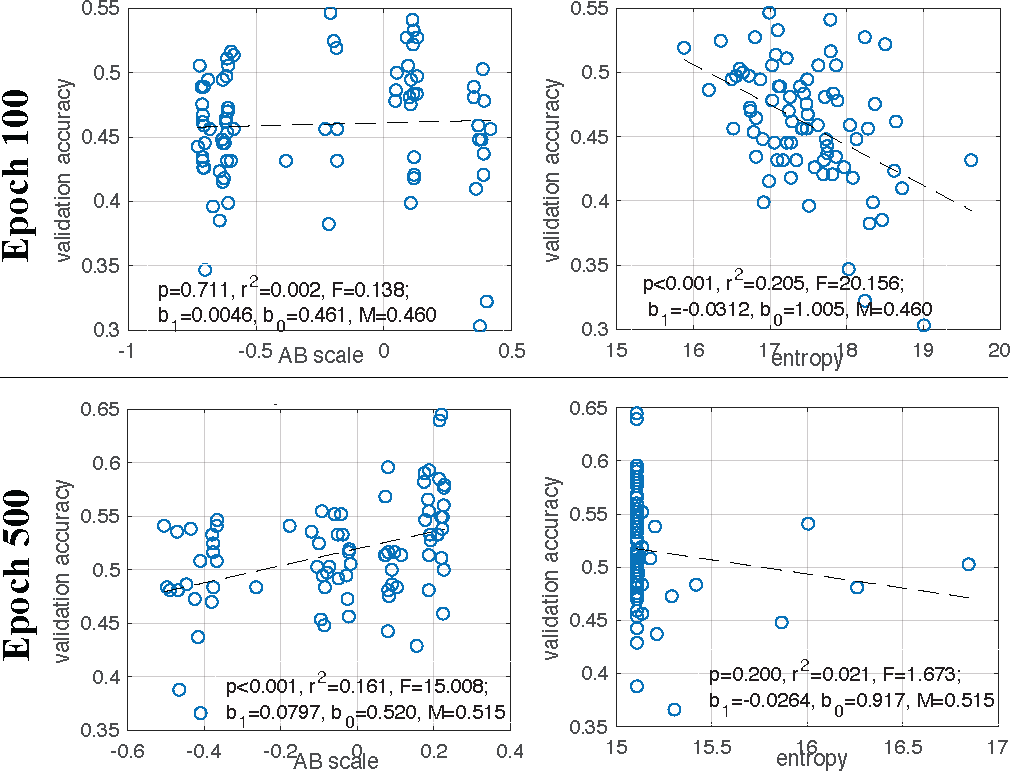
Thus, in the simulation study, higher eye movement consistency predicts higher accuracy for partially-trained models, whereas eye-gaze pattern (AB scale) does not. This results are consistent with data from typically-developing children.
Downloads
This is the DNN+HMM toolbox for modeling eye movements with deep neural networks with hidden Markov models. The models trained with the code and analysis scripts are also included.
- Files: zip file (2.8GB); README.txt
- If you use this toolbox please cite (as appropriate):
Understanding the role of eye movement consistency in face recognition and autism through integrating deep neural networks and hidden Markov models.
,
npj Science of Learning, 7:28, Oct 2022.
Publications
- Understanding the role of eye movement consistency in face recognition and autism through integrating deep neural networks and hidden Markov models.
,
npj Science of Learning, 7:28, Oct 2022. - The role of eye movement consistency in learning to recognise faces: Computational and experimental examinations.
,
In: 42nd Annual Conference of the Cognitive Science Society (CogSci), Jul 2020.
Acknowledgements
We are grateful to RGC of Hong Kong (General Research Fund # 17608621 & Collaborative Research Fund #C7129-20G).