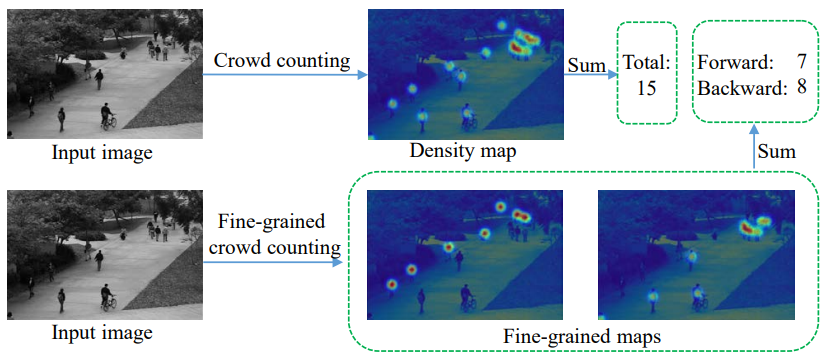
Current crowd counting algorithms are only concerned about the number of people in an image, which lacks low-level fine-grained information of the crowd. For many practical applications, the total number of people in an image is not as useful as the number of people in each sub-category. For example, knowing the number of people waiting in line or browsing can help retail stores; knowing the number of people standing/sitting can help restaurants/cafeterias; knowing the number of violent/non-violent people can help police in crowd management.
In this paper, we propose fine-grained crowd counting, which differentiates a crowd into categories based on the low-level behavior attributes of the individuals (e.g. standing/sitting or violent behavior) and then counts the number of people in each category. To enable research in this area, we construct a new dataset of four real-world fine-grained counting tasks: traveling direction on a sidewalk, standing or sitting, waiting in line or not, and exhibiting violent behavior or not. Since the appearance features of different crowd categories are similar, the challenge of fine-grained crowd counting is to effectively utilize contextual information to distinguish between categories. We propose a two branch architecture, consisting of a density map estimation branch and a semantic segmentation branch. We propose two refinement strategies for improving the predictions of the two branches. First, to encode contextual information, we propose feature propagation guided by the density map prediction, which eliminates the effect of background features during propagation. Second, we propose a complementary attention model to share information between the two branches. Experiment results confirm the effectiveness of our method.
Selected Publications
,
IEEE Trans. on Image Processing (TIP), 30:2114-2126, Jan 2021. [code | data]