
Due to the dependencies among body-joint points, human pose estimation can be considered as a structured-output learning problem. In general, human pose estimation approaches can be divided into two types: 1) prediction-based methods; 2) optimization-based methods. The first type of approach views pose estimation as a regression or detection problem, the goal of which is to learn the mapping from the input space (image features) to the target space (2D or 3D joint points), or to learn classifiers to detect specific body parts in the image. Limitations of prediction-based methods include: the manually-designed constraints might not be able to fully capture the dependencies among the body joints; poor scalability to 3D joint estimation when the search space needs to be discretized; prediction of only a single pose when multiple poses might be valid due to partial self-occlusion. Instead of estimating the target directly, the optimization-based methods learn a score function, which takes both an image and a pose as input, and produces a high score for correct image-pose pairs and low scores for unmatched image-pose pairs. For a given image, the predicted pose is the pose that maximizes the score function.
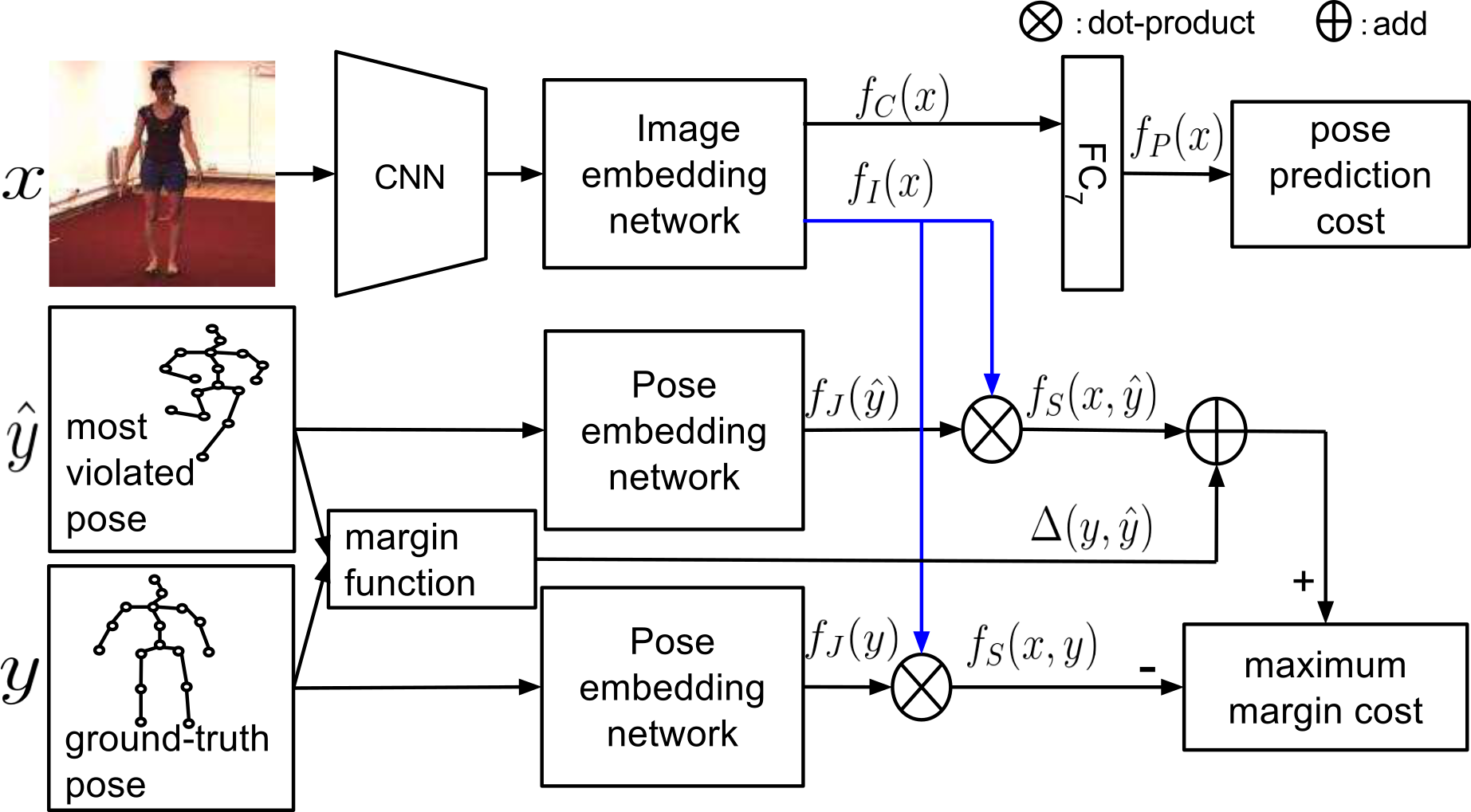
We propose a maximum-margin structured learning framework with deep neural network that learns the image-pose score function for human pose estimation. The network embeds the image and pose into a high-dimensional space, and the score function is the dot-product between the two embedding vectors. Our framework consists of three component: image feature extraction sub-network, image-embedding sub-network, and pose-embedding sub-network. The image feature extraction sub-netework is a convolution neural network that extracts both high- and mid-level image features for the image-embedding network. The specific form of the dot-product score function encourages the image-embedding network and pose-embedding network to map the image-features and pose-joints into a common space that align with each other. We use maximum-margin cost to jointly train the image-embedding and pose-embedding, which enlarges the score gap between correct image-pose pairs and incorrect ones.
During training, we optimize the network parameters with a 2-stage procedure. In the first stage, we use the score network to find the poses that most violate the maximum margin criteria for each image-pose pair. In the second stage, each image-pose pair and its corresponding most-violated pose are fed into the maximum-margin network and back-propagation is used for calculating the gradient of network parameters. Then we use line-search to determine the best step size. To encourage the image-embedding network to preserve more pose information, we also add an auxiliary pose prediction task.

Stage 1
Stage 2
We show that the learned image-pose embedding encodes semantic attributes of the pose, such as the orientation of the person and the position of the legs.
image embedding — top-2 dimensions with highest variance![BlurCanvas_kth[3_1]_ori[948_665]_blur_1000_fc_img_u_000](http://visal.cs.cityu.edu.hk/wp/wp-content/uploads/BlurCanvas_kth3_1_ori948_665_blur_1000_fc_img_u_000.png) |
corresponding pose embedding![Blur2DCanvasPose_kth[3_1]_ori[948_665]_net1_fc_0_add_correct_layout_000](http://visal.cs.cityu.edu.hk/wp/wp-content/uploads/Blur2DCanvasPose_kth3_1_ori948_665_net1_fc_0_add_correct_layout_000.png) |
image embedding – PCA coefficients with top-2 variance![PCA_kth[0_3]_fc_img_000_updated](http://visal.cs.cityu.edu.hk/wp/wp-content/uploads/PCA_kth0_3_fc_img_000_updated.png) |
corresponding pose embedding![PCA_Pose_kth[0_3]_net1_fc_0_add_correct_layout_000_updated](http://visal.cs.cityu.edu.hk/wp/wp-content/uploads/PCA_Pose_kth0_3_net1_fc_0_add_correct_layout_000_updated.png) |
Selected Publication
- Maximum-Margin Structured Learning with Deep Networks for 3D Human Pose Estimation.
,
In: Intl. Conf. on Computer Vision (ICCV):2848-2856, Santiago, Dec 2015. [spotlight video] - Maximum-Margin Structured Learning with Deep Networks for 3D Human Pose Estimation.
,
International Journal of Computer Vision (IJCV), 122(1):149-168, March 2017.
Demo
- Trajectory of embedding feature (mov)
- Estimation comparison (mov)