
Motivation:
- RNNs have to be calculated step-by-step, which is not easily parallelized.
- There is a long path between the start and end of the sentence using RNNs. Tree structures can make a shorter path, but trees require special processing.
- Convolutional decoders are able to learn multi-level representations of concepts, and each of them should correspond to an image area, which should benefit word prediction.
Single-level Attention VS Multi-level Attention
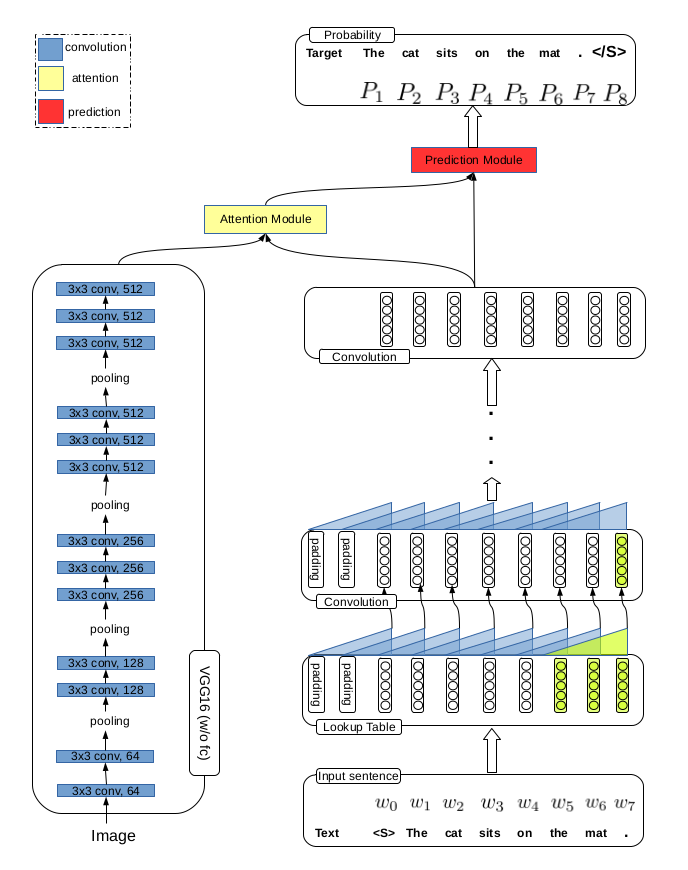
The single-level attention model is similar to the LSTM-based captioning models, which employs the top layer concept representations to compute the attention weights. However, the advantage of our convolutional decoder is to obtain multi-level representations of concepts and it is believed that leveraging the information could benefit caption generation, therefore, the multi-level attention mechanism is developed.
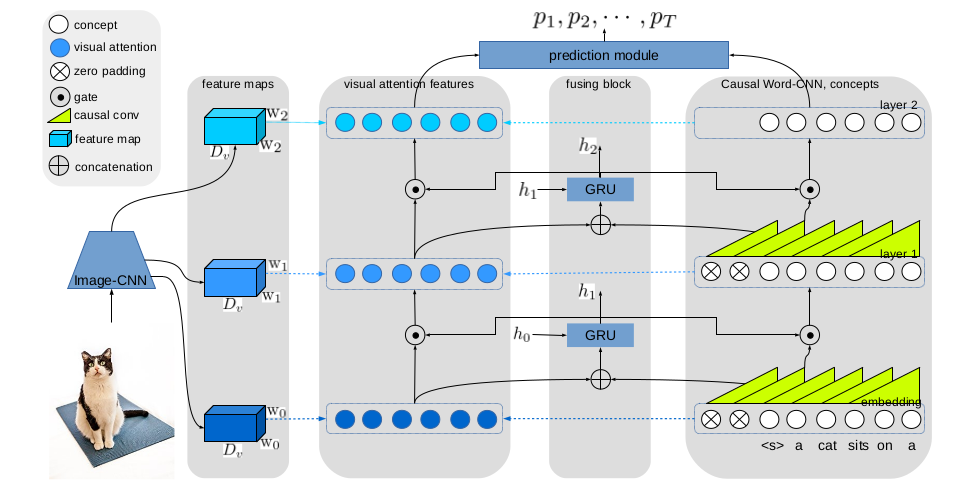
There are for parts: (1) Image-CNN: to obtain a feature representation of an image. (2) Causal Word-CNNs: to merge words to obtain a high-level representation of the sentence. (3) Visual attention: to learn the correspondence between concepts and image areas, which is composed of attended visual features for this layer and the gated visual features from the previous layer. (4) Fusing block: to fuse the low-level concepts and the corresponding visual attention features.
Multi-level attention model significantly improves the performance, e.g., the CIDEr score increases from 0.923 to 0.999 using GHA. Other observations are that (1) deeper Word-CNN cannot obtain better performance. The average length of the sentences in MSCOCO dataset is 11.6 and a 6-layer Word-CNN is enough. (2) Using multi-scale (MS) feature maps reduces all metric scores. Low-level features could not benefit word prediction.
Publications
- CNN+CNN: Convolutional Decoders for Image Captioning.
,
In: IEEE Computer Vision and Pattern Recognition: Language and Vision Workshop, Salt Lake City, Jun 2018. [github] - Gated Hierarchical Attention for Image Captioning.
,
In: Asian Conference on Computer Vision (ACCV), Perth, Dec 2018. [github]