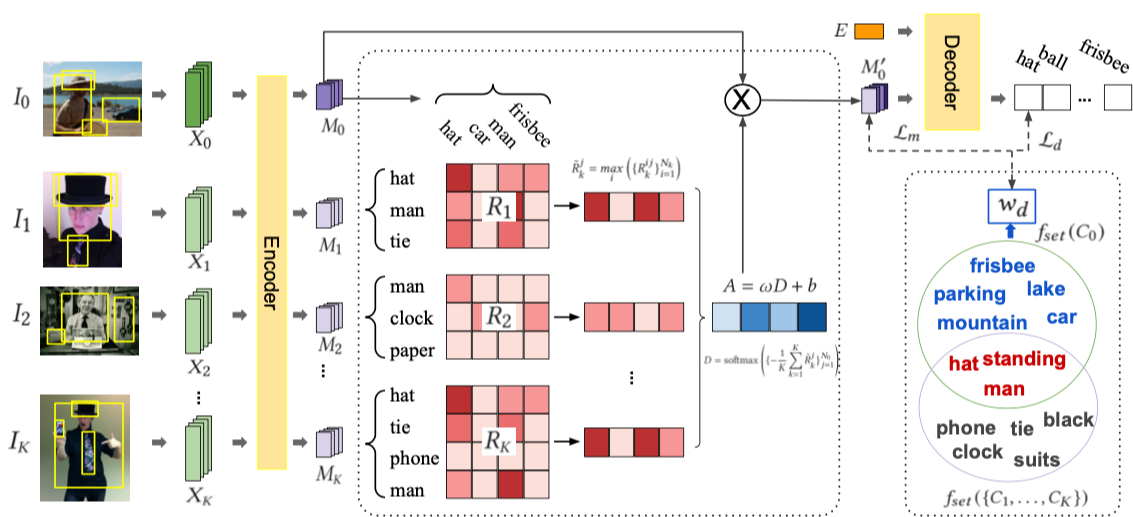
Describing images using natural language is widely known as image captioning, which has made consistent progress due to the development of computer vision and natural language generation techniques. Though conventional captioning models achieve high accuracy based on popular metrics, i.e., BLEU, CIDEr, and SPICE, the ability of captions to distinguish the target image from other similar images is under-explored. To generate distinctive captions, a few pioneers employ contrastive learning or re-weighted the ground-truth captions, which focuses on one single input image. However, the relationships between objects in a similar image group (e.g., items or properties within the same album or fine-grained events) are neglected. In this paper, we improve the distinctiveness of image captions using a Group-based Distinctive Captioning Model (GdisCap), which compares each image with other images in one similar group and highlights the uniqueness of each image. In particular, we propose a group-based memory attention (GMA) module, which stores object features that are unique among the image group (i.e., with low similarity to objects in other images). These unique object features are highlighted when generating captions, resulting in more distinctive captions. Furthermore, the distinctive words in the ground-truth captions are selected to supervise the language decoder and GMA. Finally, we propose a new evaluation metric, distinctive word rate (DisWordRate) to measure the distinctiveness of captions. Quantitative results indicate that the proposed method significantly improves the distinctiveness of several baseline models, and achieves the state-of-the-art performance on both accuracy and distinctiveness. Results of a user study agree with the quantitative evaluation and demonstrate the rationality of the new metric DisWordRate.
Selected Publications
,
In: ACM Multimedia (MM), Oct 2021 (oral). [supplemental]