 3D human pose estimation and tracking has been researched for over two decades. Applications include markerless Motion Capture to collect human or other articulated object’s movement data without being limited to a lab environment. Also, it can be used for Human-Computer Interaction, by tracking and recognizing the human’s action. In some cases, the multi-target human pose tracking and recognition could be applied to surveillance.
3D human pose estimation and tracking has been researched for over two decades. Applications include markerless Motion Capture to collect human or other articulated object’s movement data without being limited to a lab environment. Also, it can be used for Human-Computer Interaction, by tracking and recognizing the human’s action. In some cases, the multi-target human pose tracking and recognition could be applied to surveillance.
Pose tracking is a high-dimensional optimization problem with multiple local maxima. The human pose configuration is a high-dimensional (40 DoFs) state space. The motion of a human is usually complex: limbs move with a wide range of motion and speeds, causing frequent occlusions of body parts, while typical image features such as silhouettes and edges are not robust to partial self-occlusions. That makes occluded and overlapping body parts hard to localize. Recent supervised learning approaches simplify and constrain the problem: learning a strong action-specific motion priors to predict the next pose from previous poses; learning a regression model to directly map from image features to the poses. But supervised methods are data-driven and have difficulty recovering poses that are far from those present in the training set. For supervised methods, tracking highly depends on the quality of training data, and the noise in ground-truth poses will be learned inadvertently.
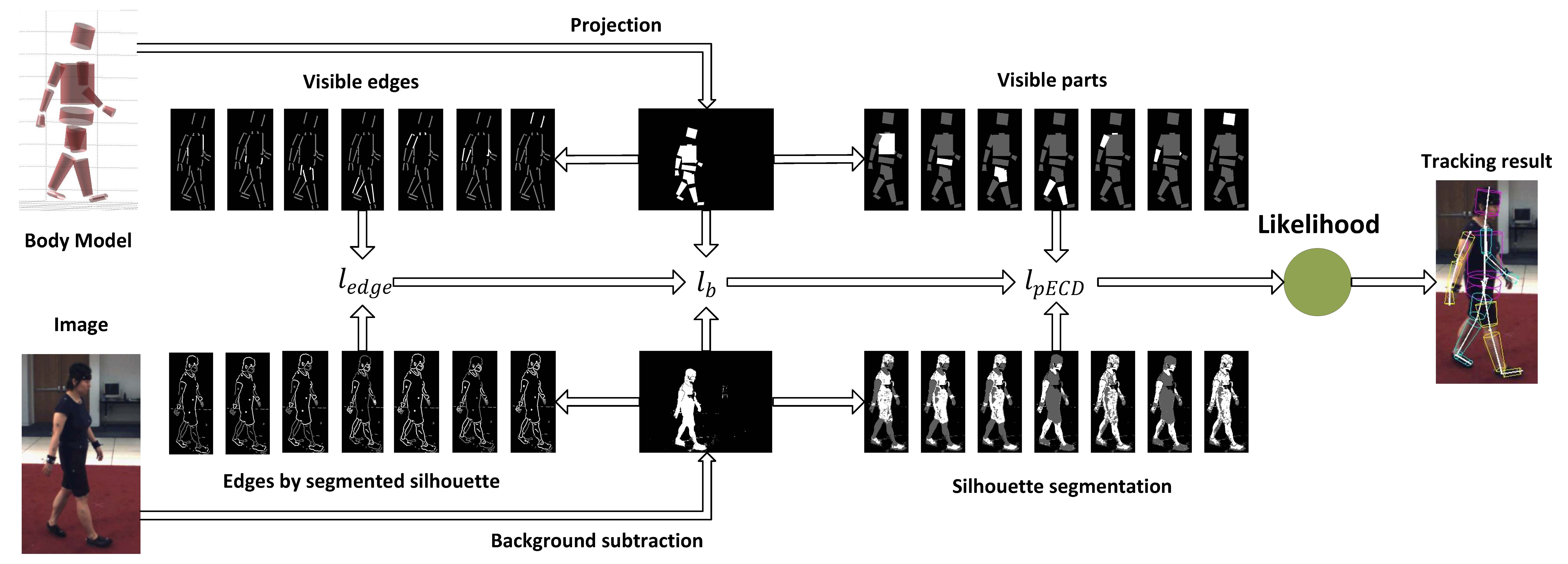
In this project, we develop a unsupervised robust part-based likelihood function, which is based on the exponential Chamfer distance between visible projected parts and silhouette segments, and between visible part edges and edges in the silhouette segment. The exponential transformation of the Chamfer distance better aligns the limbs, making the likelihood function smoother and easier to optimize using a standard annealing particle filter (APF). Our part-based model helps to localize occluded parts by matching them only to the segmented visible parts. Our method benefits when a part can be segmented well, but is not greatly affected by poorly-segmented parts, since these will be matched to the original silhouettes.
We tested our robust likelihood function on the HumanEva dataset, and it performed significantly better than other unsupervised tracking methods. After correcting for the bias of the mocap joint systen, our part-based likelihood function also performs comparably to the current state-of-the-art supervised method.
Publications
- A Robust Likelihood Function for 3D Human Pose Tracking.
,
IEEE Trans. on Image Processing (TIP), 23(12):5374-5389, Dec 2014.
Demos/Results