2026
2025
2024
2023
2022
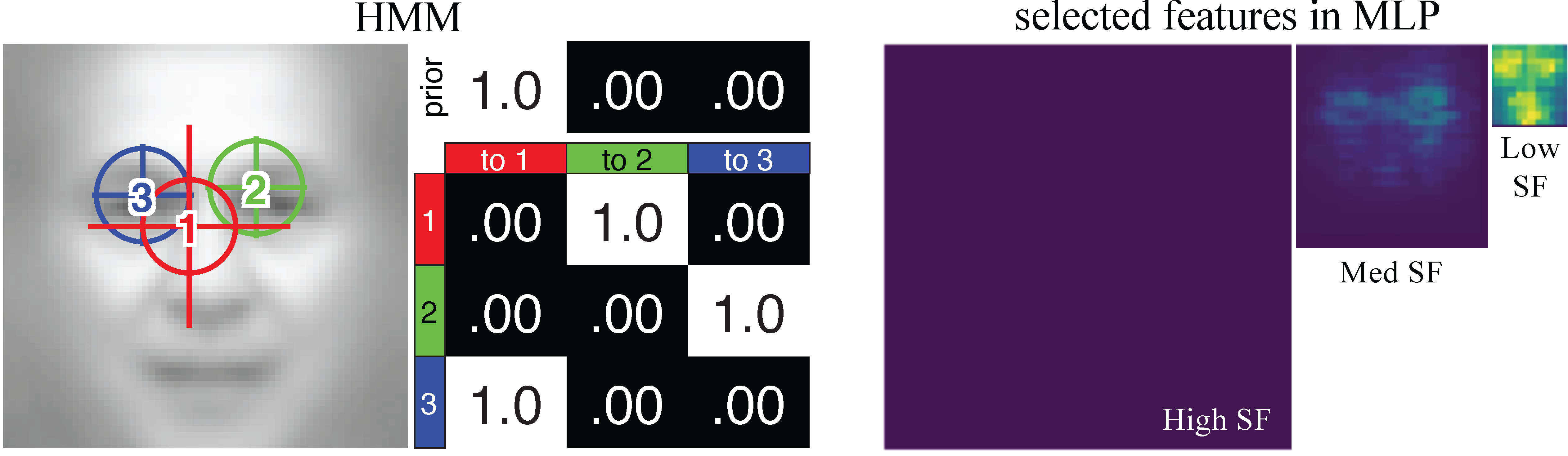
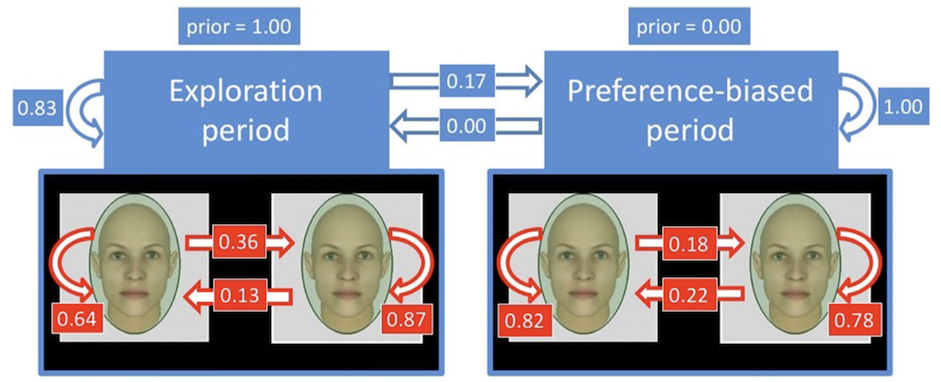
This is the toolbox for modeling eye movements and feature learning with deep neural networks and hidden Markov models (DNN+HMM).Modeling Eye Movements with Deep Neural Networks and Hidden Markov Models (DNN+HMM)
,
npj Science of Learning, 7:28, Oct 2022.
2021
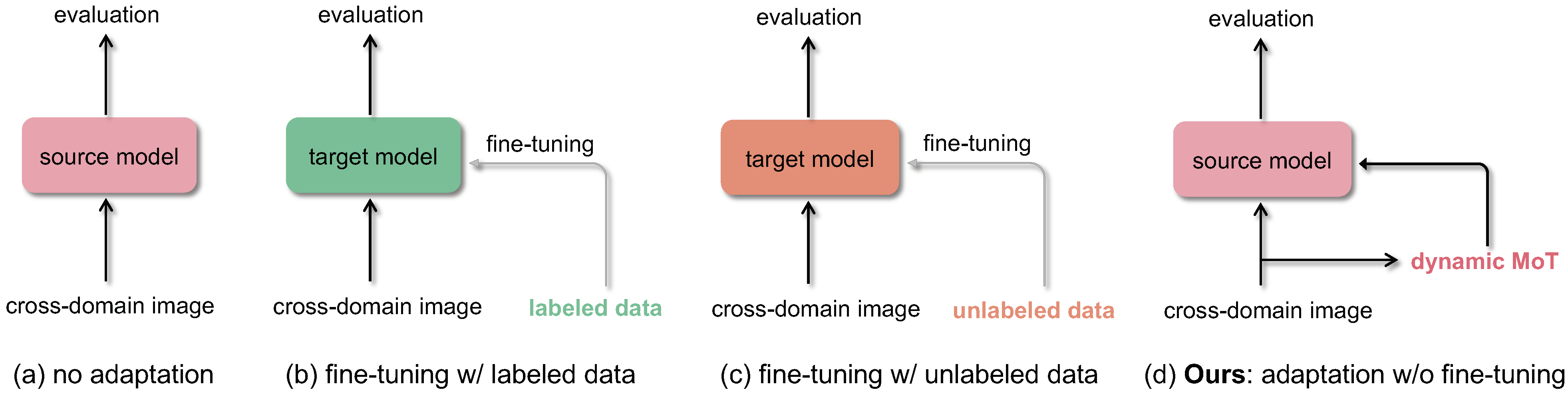
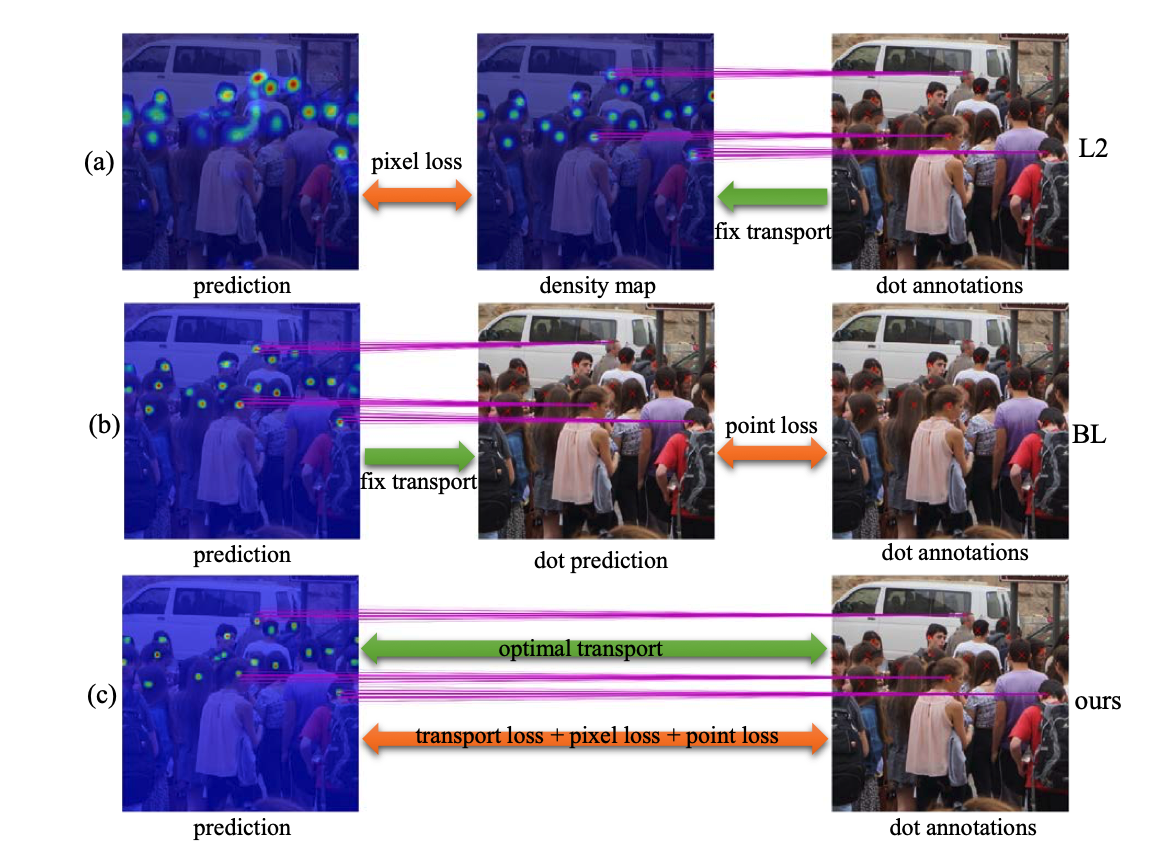
A dataset consisting of Chinese White Dolphin (CWD) and distractors for detection tasks. Generalized loss function for crowd counting. Synthetic dataset for cross-view cross-scene multi-view counting. The dataset contains 31 scenes, each with about ~100 camera views. For each scene, we capture 100 multi-view images of crowds. Generalized loss function for crowd counting. Dataset for fine-grained crowd counting, which differentiates a crowd into categories based on the low-level behavior attributes of the individuals (e.g. standing/sitting or violent behavior) and then counts the number of people in each category. This is a python toolbox learning parametric manifolds of Gaussian mixture models (GMMs).Dolphin-14k: Chinese White Dolphin detection dataset

,
In: ACM Multimedia Asia (MMAsia), Gold Coast, Australia, Dec 2021. Crowd counting: Zero-shot cross-domain counting
,
In: ACM Multimedia (MM), Oct 2021. CVCS: Cross-View Cross-Scene Multi-View Crowd Counting Dataset

,
In: IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR):557-567, Jun 2021. Crowd counting: Generalized loss function
,
In: IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Jun 2021. Fine-Grained Crowd Counting Dataset

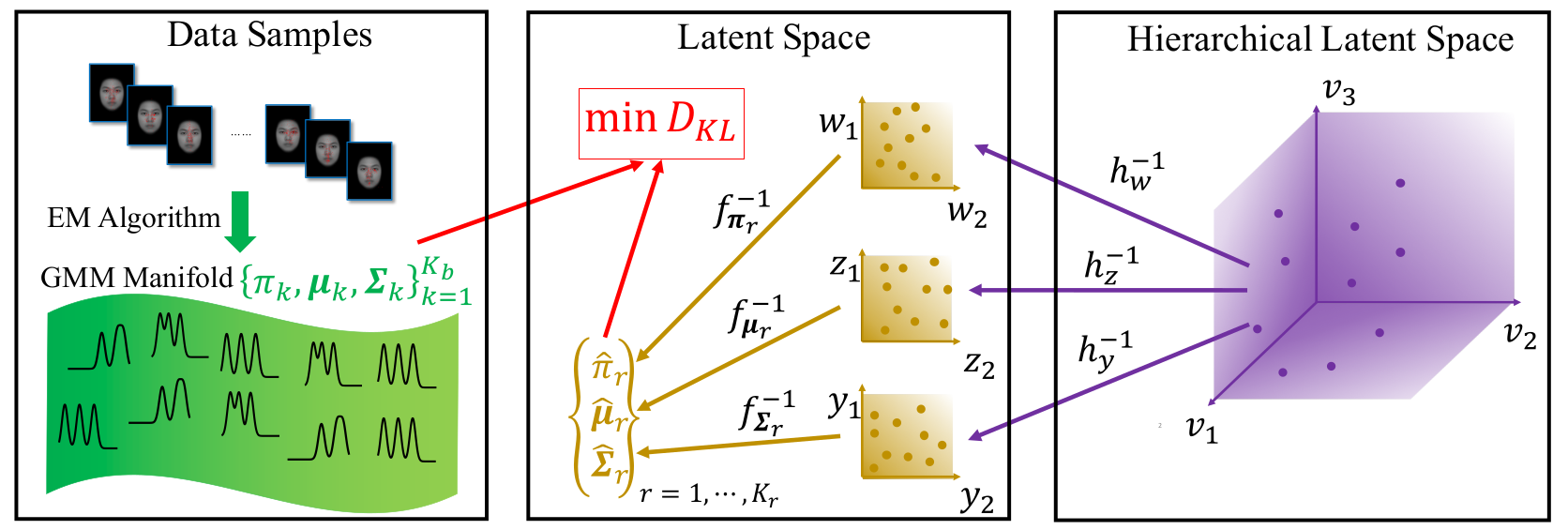
Parametric Manifold Learning of Gaussian Mixture Models (PRIMAL-GMM) Toolbox
,
IEEE Trans. on Pattern Analysis and Machine Intelligence (TPAMI), 44(6):3197-3211, June 2022 (online 2021).
2020
Modeling noisy annotations in crowd counting: NoisyCC. Recurrently optimized tracking with ROAM and ROAM++.Crowd counting: Modeling noisy annotations
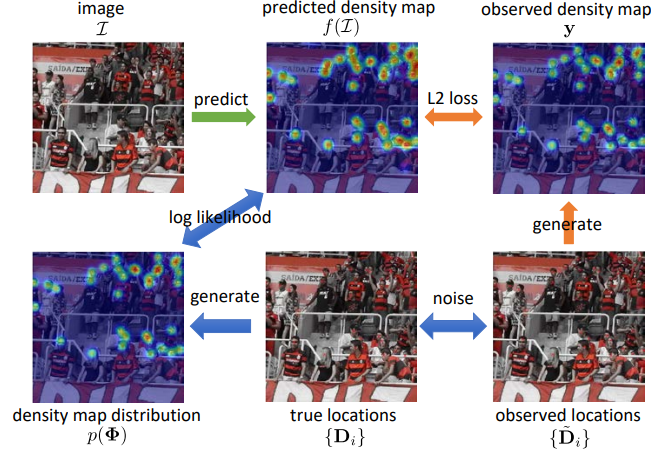
,
In: Neural Information Processing Systems (NeurIPS), Dec 2020. Visual Object Tracking: ROAM and ROAM++
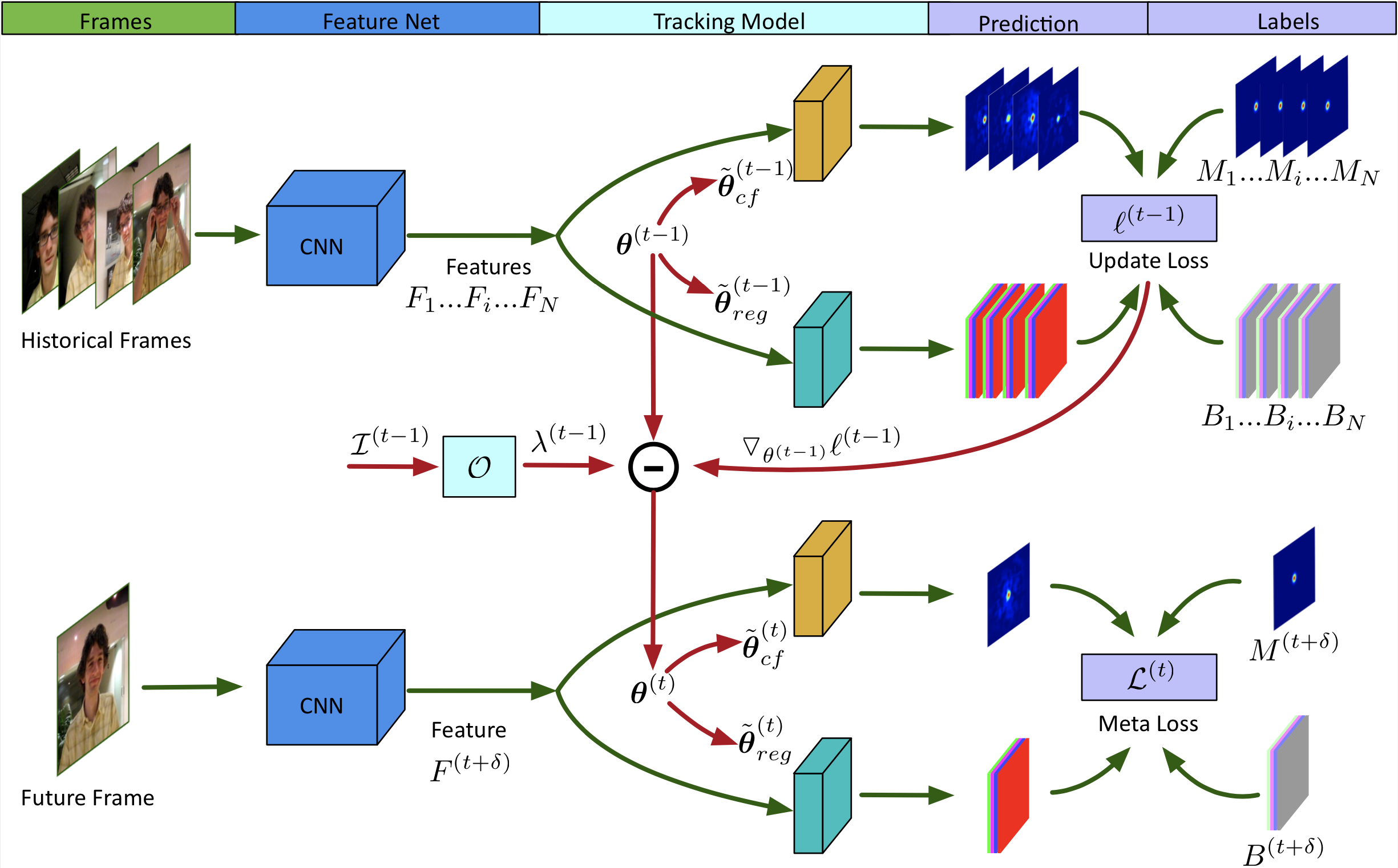
,
In: IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, Jun 2020.
2019
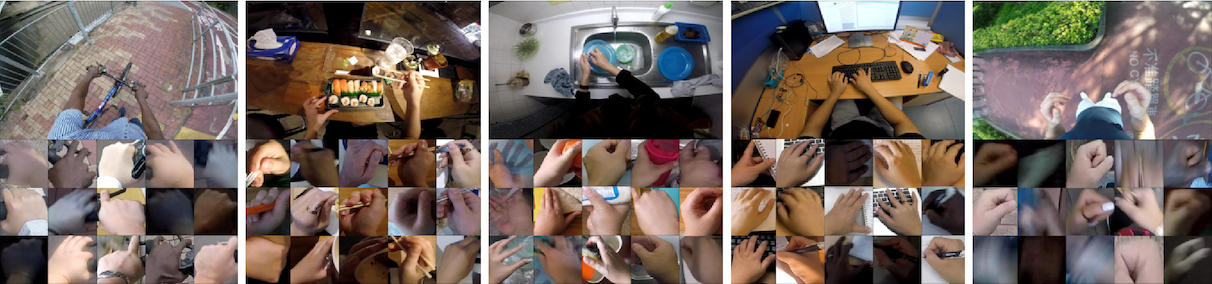
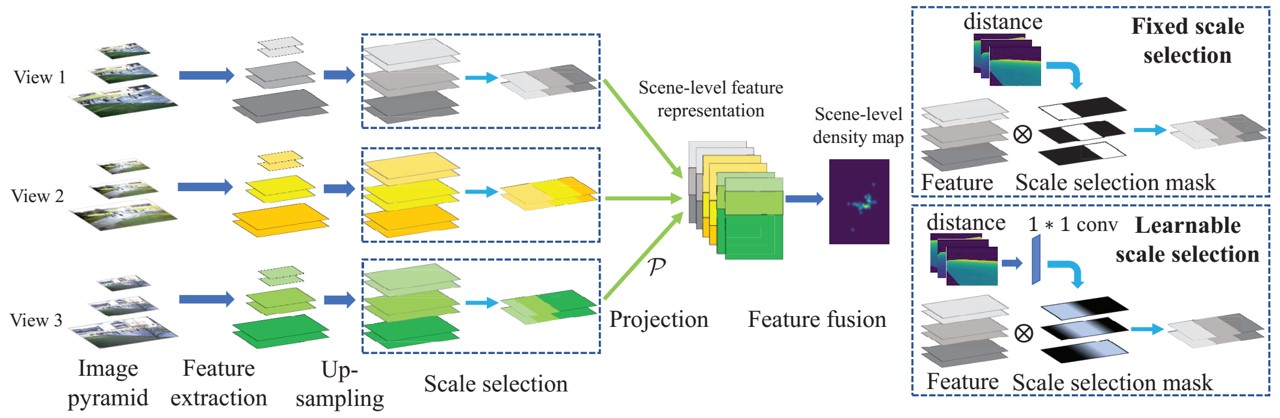
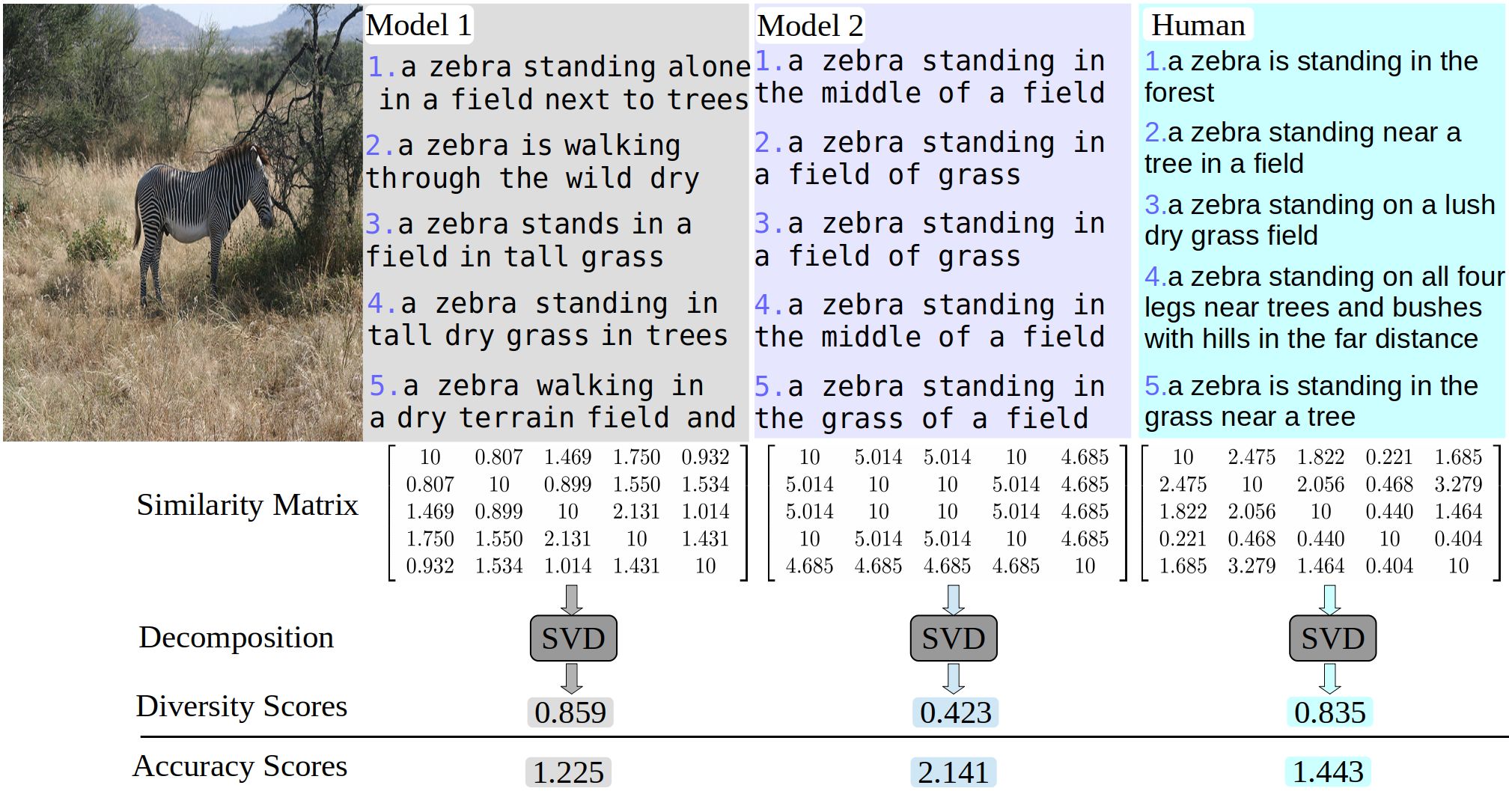
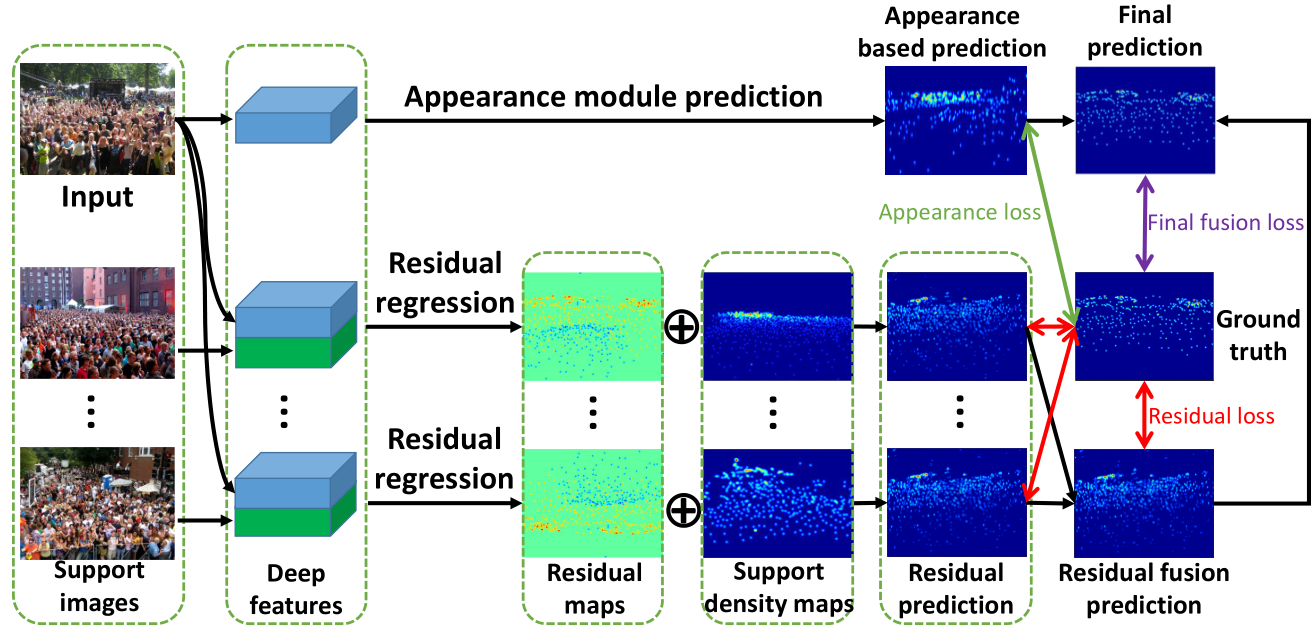
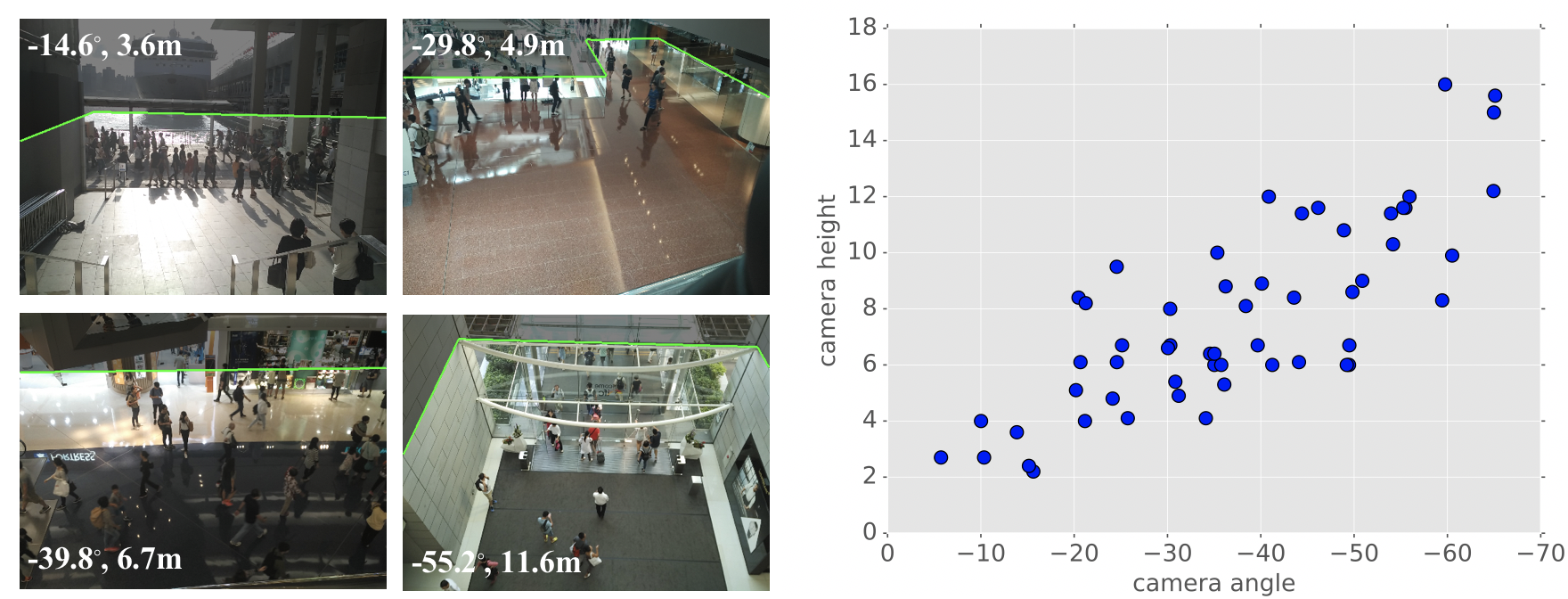
KDMG for crowd counting. This is a MATLAB toolbox for analyzing eye movement data using switching hidden Markov models (SHMMs), for analyzing eye movement data in cognitive tasks involving cognitive state changes. It includes code for learning SHMMs for individuals, as well as analyzing the results. Egocentric hand detection dataset with variability on people, activities and places, to simulate daily life situations. Datasets for multi-view crowd counting in wide-area scenes. Includes our CityStreet dataset, as well as the counting and metadata for multi-view counting on PETS2009 and DukeMTMC. The code/model for wide-area crowd counting using multiple views: multi-view multi-scale (MVMS) model. Toolbox for computing diversity metrics for image captioning. The code/model for crowd counting using residual regression and semantic prior. Crowd counting dataset of indoor/outdoor scenes with extrinsic camera parameters (camera angle and height), for use as side information. Toolboxes for density-preserving HEM algorithm for simplifying mixture models.Crowd counting: Kernel-based density map generation
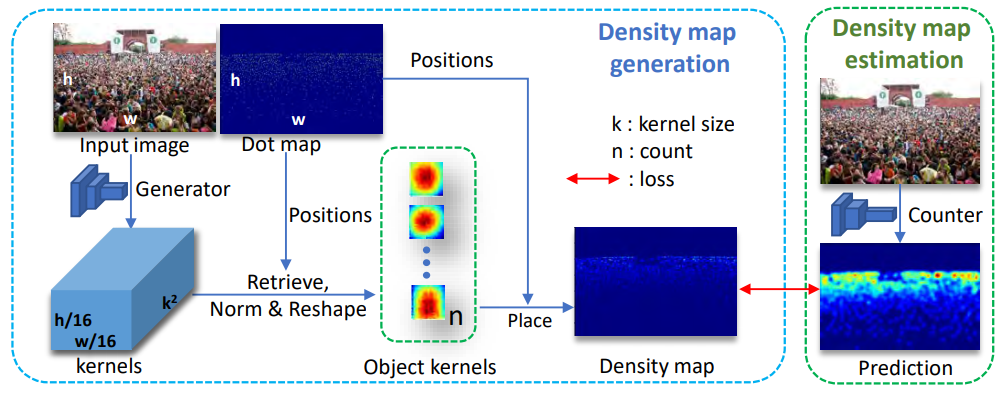
,
IEEE Trans. Pattern Analysis and Machine Intelligence (TPAMI), 44(3):1357-1370, Mar 2022. Eye Movement analysis with Switching HMMs (EMSHMM) Toolbox
,
Behavior Research Methods, 52:1026-1043, June 2020. EgoDaily – Egocentric dataset for Hand Disambiguation
,
Image and Vision Computing, 89:131-143, Sept 2019. CityStreet: Multi-view crowd counting dataset

,
In: IEEE/CVF Conf. on Computer Vision and Pattern Recognition (CVPR), Long Beach, June 2019. Crowd counting: Multi-view Multi-scale (MVMS) counting
,
In: IEEE/CVF Conf. on Computer Vision and Pattern Recognition (CVPR), Long Beach, June 2019. Image Captioning: Diversity Metrics
,
IEEE Trans. on Pattern Analysis and Machine Intelligence (TPAMI), 44(2):1035-1049, Feb 2022. Crowd counting: residual regression with semantic prior
,
In: IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , Long Beach, June 2019. CityUHK-X: crowd dataset with extrinsic camera parameters
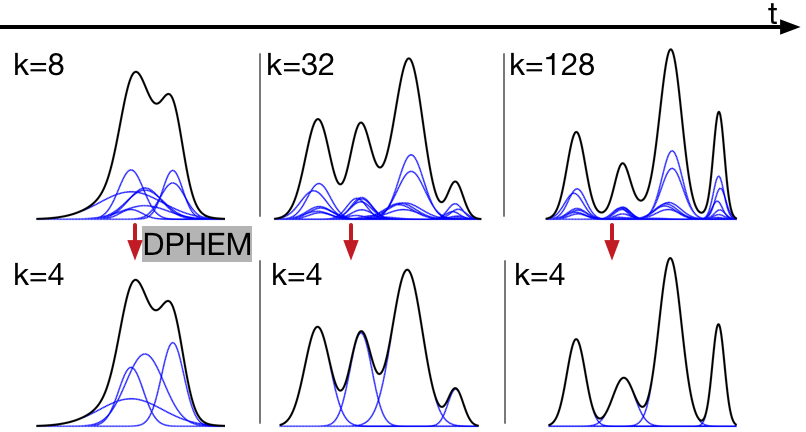
,
In: Neural Information Processing Systems, Long Beach, Dec 2017. DPHEM toolbox for simplifying GMMs
,
IEEE Trans. on Pattern Analysis and Machine Intelligence (TPAMI), 41(6):1323-1337, June 2019.
2018
The code/model for GHA for image captioning. The code/models for MemTrack and MemDTC for visual object trackingImage Captioning: Gated Hierarchical Attention
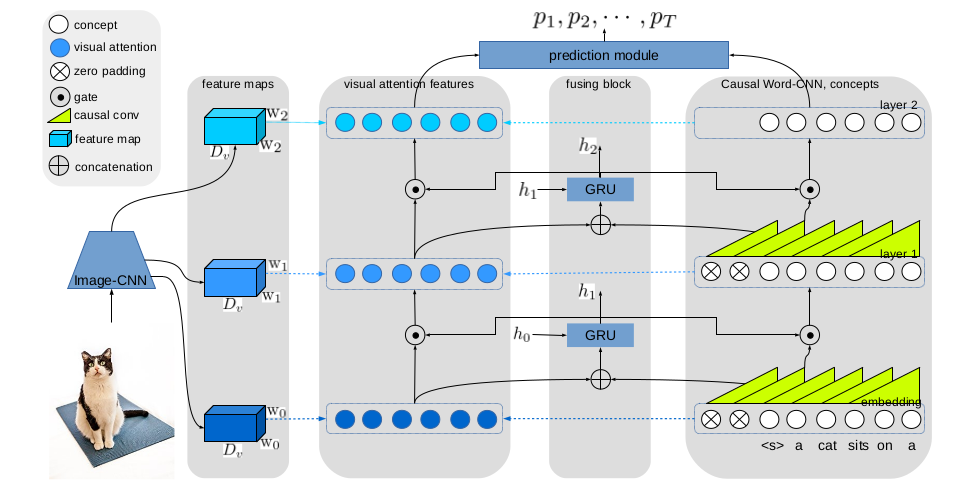
,
In: Asian Conference on Computer Vision (ACCV), Perth, Dec 2018. Visual Object Tracking: MemTrack and MemDTC
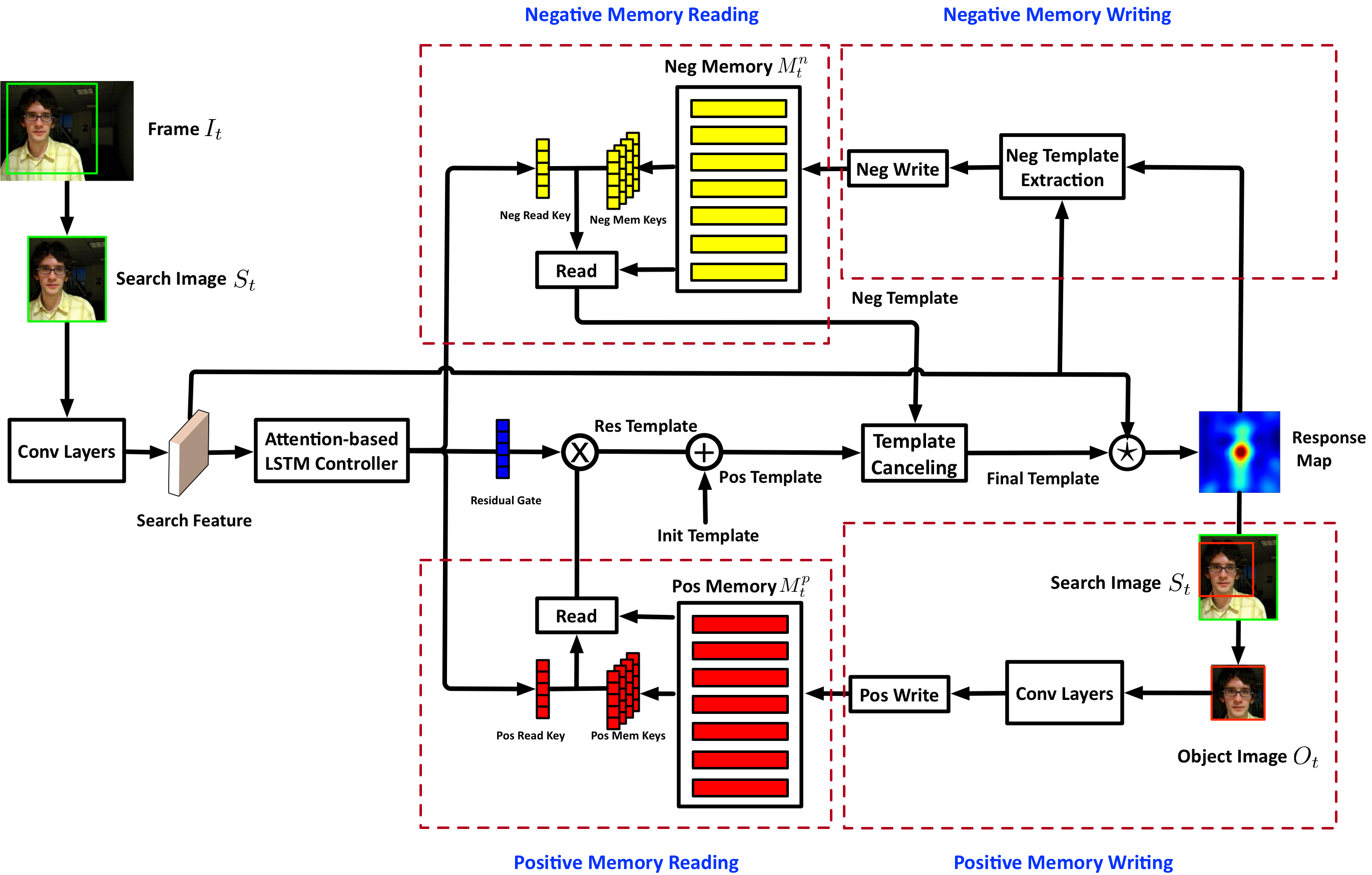
,
IEEE Trans. on Pattern Analysis and Machine Intelligence (TPAMI), 43(1):360-374, Jan 2021.
2017
This is a code/model for Recurrent Filter Learning for VOT. A multi-view and stereo-depth dataset for 3D human pose estimation, which consists of challenging martial arts actions (Tai-chi and Karate), dancing actions (hip-hop and jazz), and sports actions (basketball, volleyball, football, rugby, tennis and badminton). This is a MATLAB toolbox for analyzing eye movement data using hidden Markov models. It includes code for learning HMMs for individuals, as well as clustering indivduals’ HMMs into groups.Visual Object Tracking: Recurrent filter learning
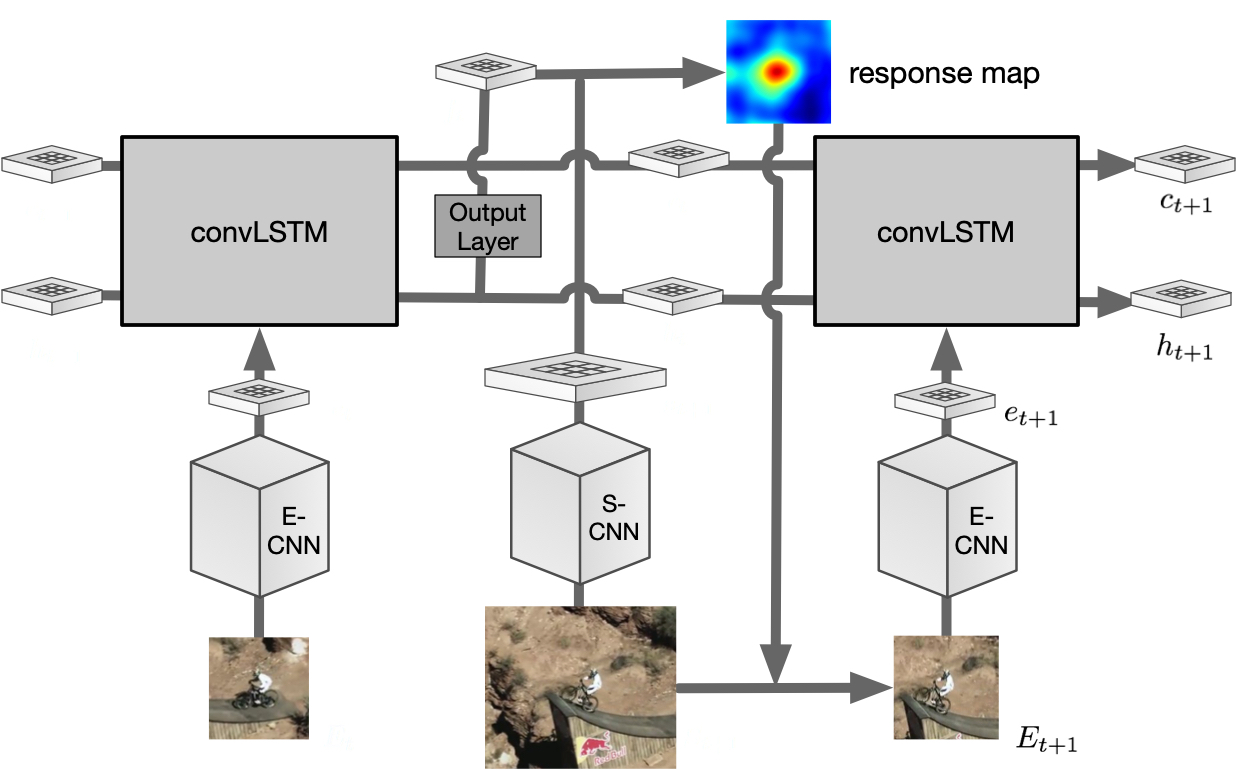
,
In: ICCV 5th Visual Object Tracking Challenge Workshop VOT2017, Venice, Oct 2017. MADS: Martial Arts, Dancing, and Sports Dataset

,
Image and Vision Computing, 61:22-39, May 2017. Eye Movement Hidden Markov Models (EMHMM) Toolbox
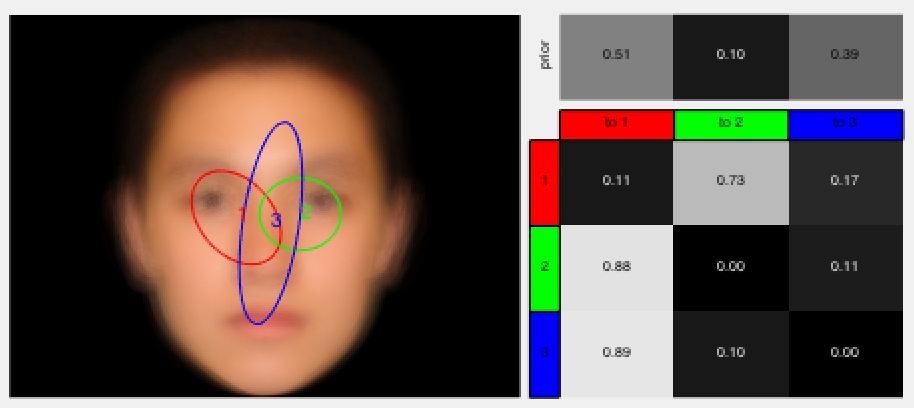
,
Journal of Vision, 14(11):8, Sep 2014.
2016
This is a MATLAB toolbox for automatically extracting the panels from digital manga/comic pages. The VarBB toolbox is an implementation for the variational branch-and-bound algorithm for Bregman ball trees (bb-trees). VarBB can speed up nearest neighbor search for generative models. This is a MATLAB toolbox for clustering hidden Markov models using the variational HEM algorithm. The toolbox can also estimate HMM mixtures (H3M) using the EM algorithm. Images of small objects for small instance detections. Currently four object types are available.Manga panel extraction toolbox
VarBB Toolbox
,
In: International Conference on Machine Learning (ICML), Atlanta, Jun 2013. H3M toolbox
,
Journal of Machine Learning Research (JMLR), 15(2):697-747, Feb 2014. Small Object Dataset

,
In: IEEE Conf. Computer Vision and Pattern Recognition (CVPR), Boston, Jun 2015.
2015
2014
This is an OpenCV C++ library for Dynamic Teture (DT) models. It contains code for the EM algorithm for learning DTs and DT mixture models, and the HEM algorithm for clustering DTs, as well as DT-based applications, such as motion segmentation and Bag-of-Systems (BoS) motion descriptors. This is a toolbox for generalized Gaussian process models (GGPM). The toolbox is implemented as an add-on to the GPML toolbox for Matlab/Octave. The toolbox contains likelihood functions for GGPMs, as well as a Taylor inference function. GPML version 3.4 is supported.libdt – OpenCV library for Dynamic Textures
,
IEEE Trans. on Pattern Analysis and Machine Intelligence (TPAMI), 30(5):909-926, May 2008.
,
IEEE Trans. on Pattern Analysis and Machine Intelligence (TPAMI), 35(7):1606-1621, Jul 2013. Generalized Gaussian Process Models Toolbox
,
In: IEEE Conf. Computer Vision and Pattern Recognition (CVPR), Colorado Springs, Jun 2011.
2013
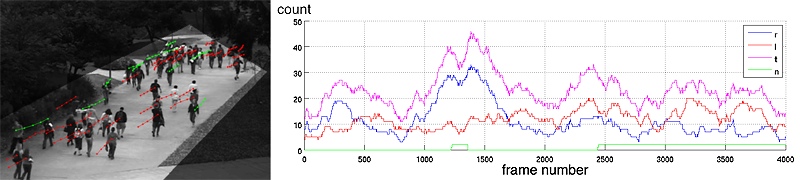
Videos can be obtained from the DynTex website. The text files contain the list of selected tags, the list of selected videos and ground-truth tags, and the training/test set splits. Video of people on pedestrian walkways at UCSD, and the corresponding motion segmentations. Currently two scenes are available. People annotations, perspective density maps, region-of-interest, and crowd counts for the UCSD Pedestrian Dataset. The features and counts for people counting on the UCSD Dataset. This data should be sufficient if you are interested in the regression problem only. Includes the Peds1, Peds2, and CVPR counting datasets. The features and counts for people counting on the PETS2009 Dataset. Also includes the segmentations, perspective maps, and ground-truth annotations. These are the ground-truth annotations for line counting on the UCSD, Grand Central, and LHI datasets.Experimental setup for semantic video texture annotation on the DynTex dataset
,
IEEE Trans. on Pattern Analysis and Machine Intelligence (TPAMI), 35(7):1606-1621, Jul 2013. UCSD Pedestrian Dataset

,
IEEE Trans. on Pattern Analysis and Machine Intelligence (TPAMI), 30(5):909-926, May 2008. People Annotations for UCSD Dataset
,
IEEE Trans. on Image Processing (TIP), 21(4):2170-2177, May 2012. People Counting Data for UCSD Dataset
,
IEEE Trans. on Image Processing (TIP), 21(4):2170-2177, May 2012. People Counting Data for PETS2009 Dataset
,
In: 11th IEEE Intl. Workshop on Performance Evaluation of Tracking and Surveillance (PETS 2009), Miami, Jun 2009. Line Counting Dataset

,
IEEE Trans. on Circuits and Systems for Video Technology (TCSVT), 26(10):1955-1969, Oct 2016.
,
In: IEEE Conf. Computer Vision and Pattern Recognition (CVPR), Portland, Jun 2013.
2012
Dataset of manga panel layouts.Manga Layout Dataset
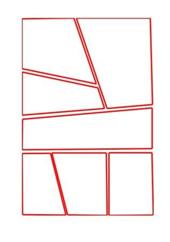
,
ACM Transactions on Graphics (Proc. SIGGRAPH Asia 2012), Singapore, Nov 2012.
2011
A video of boats moving through water. A challenging background subtraction task, where the background itself is moving. Ground-truth annotations of the musical keys of songs in the GTZAN music genre dataset.Boats Videos

,
Machine Vision and Applications, 22(5):751-766, Sep 2011. Key annotations for the GTZAN music genre dataset
,
In: Intl. Conference on MultiMedia Modeling (MMM), Taipei, Jan 2011.