Qualitative Results

The above figure (left) displays the captions generated by four models for one similar image group. Overall, all the methods generate accurate captions specifying the salient content in the image. However, their performances on the distinctiveness differ. M2Transformer and DiscCap generate captions that only mention the most salient objects in the image, using less distinctive words. For instance, in column 1, our GdisCap generates captions ”a dog sitting in front of the water looking at boats”, compared to the simpler caption ”a dog sitting on a dock in the water” from M2Transformer. Similarly, in column 3, our GdisCap describes the most distinctive property of the target image, the ”santa hat”, compared to DiscCap that only provides ”two dogs laying on the ground”.
Figure Right: Visualization of the similarity matrix and distinctive attention . Here we show the second image (in red box) as the target image I0 and display the similarity value between four salient objects in I0 and the objects in the other four images. The attention denotes the overall distinctiveness of each object in the image I0. Objects in the same colored box are from the same image.
Quantitative Results
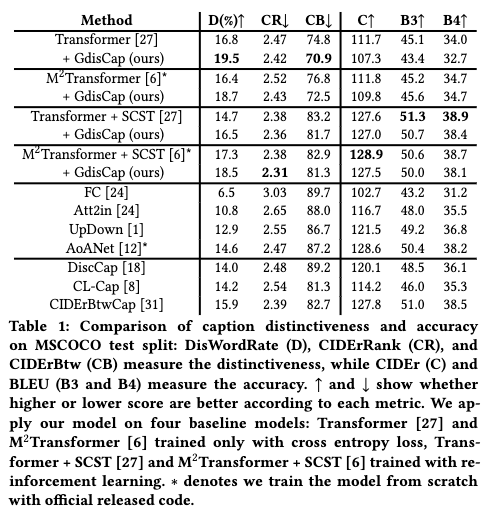
The main experiment results are presented in Table 1, and we make the following three observations:
- First, when applied to four baseline models, our model achieves impressive improvement for the distinctive metrics, while maintaining comparable results on accuracy metrics.
- Second, in terms of distinctiveness, models trained with cross-entropy loss tend to perform better than models trained with SCST.
- Third, compared with state-of-the-art models that improve the accuracy of generated captions, our model M2Transformer + SCST + GdisCap achieves comparable accuracy, while gaining impressive improvement in distinctness.

To fairly evaluate the distinctiveness of our model from the human perspective, we propose a caption-image retrieval user study. The users are instructed to choose the target image that the caption best describes. A higher retrieval score indicates more distinctiveness of the generated caption, i.e., it can distinguish the target image from other similar images (more details are in the paper).
We compare our GdisCap model with three competitive models, DiscCap, CIDErBtwCap, and M2Transformer+SCST. The results are shown in Table 3, where our model achieves the highest caption-image retrieval accuracy — 68.2 compared to M2Transformer+SCST with 61.9.