Compared to single cameras, multi-camera networks allow better understanding and modeling of the 3D world through more densely sampling of information in a 3D scene. Multi-camera based vision tasks have been a popular research field, especially deep learning related tasks, such as 3D pose estimation from multiple 2D observations, 3D reconstruction, multi-view tracking, and multi-view crowd counting. For these multi-view tasks, it is usually assumed that the multi-cameras are temporally synchronized when designing DNNs models, i.e., all cameras capture images at the same time point. However, the synchronization assumption for multi-camera systems may not always be valid in practical applications due to a variety of reasons, such as dropped camera frames due to limited network bandwidth or system resources, network transmission delays, etc. Thus, handling unsynchronized multi-cameras is an important issue in the adoption and practical usage of multiview computer vision.
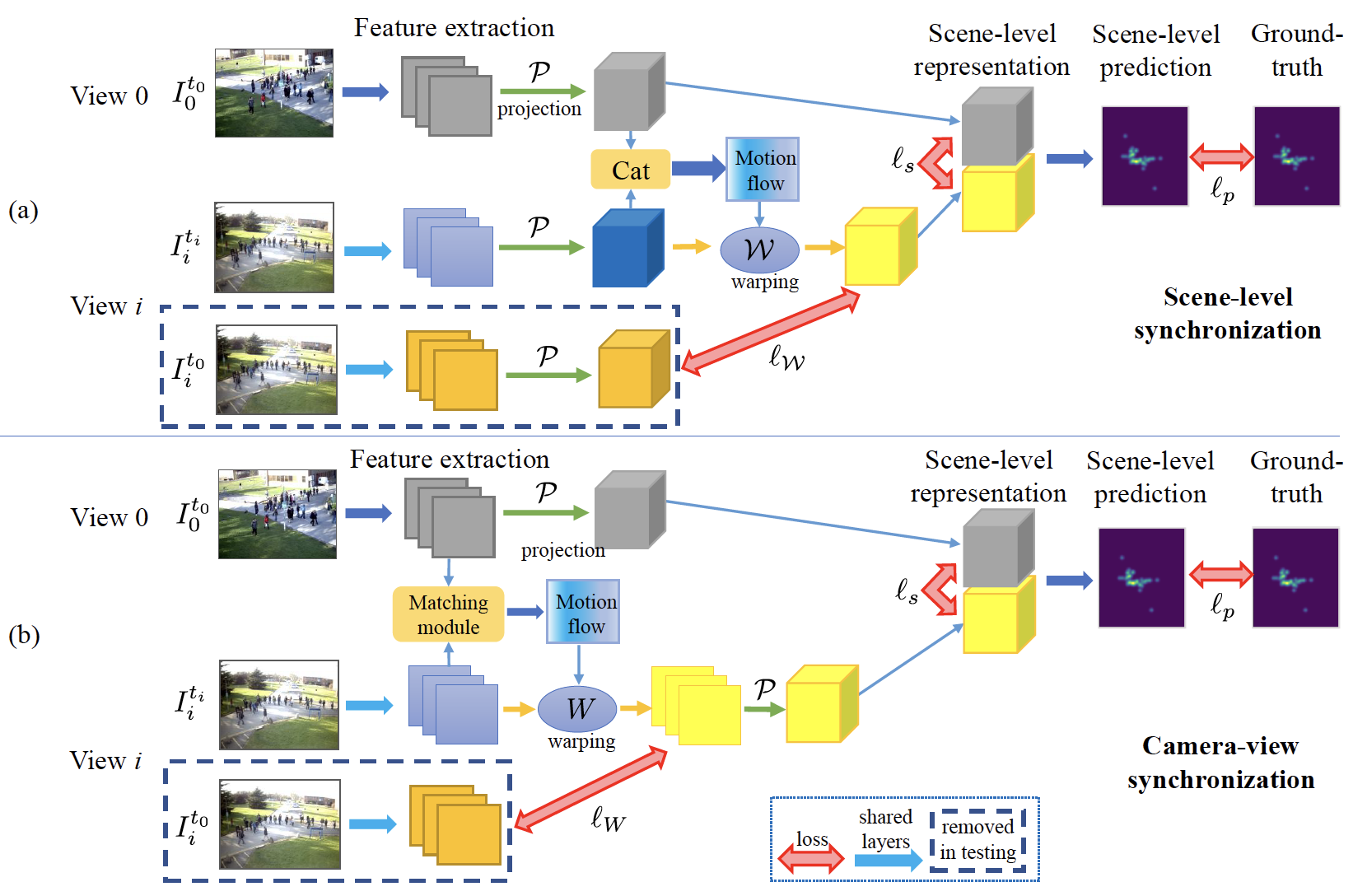
In this paper, we consider the regime of low-fps multiview camera systems – we only assume that a single relevant image is captured from each camera, and thus the input is a set of unsynchronized multi-camera images. We propose a synchronization model that operates in conjunction with existing DNN-based multi-view models to allow them to work on unsynchronized data. Our proposed model first synchronizes other views to a reference view using a differentiable module, and then the synchronized multi-views features are fused and decoded to obtain the task-oriented output. We consider two variants of our model that perform synchronization at different stages in the pipeline: 1) scene-level synchronization performs the synchronization after projecting the camera features to their 3D scene representation; 2) camera-level synchronization performs the synchronization between camera views first, and then projects the synchronized 2D feature maps to their 3D representations. In both cases, motion flow between the cameras’ feature maps are estimated and then used to warp the feature maps to align with the reference view (either at the scene-level or the camera-level). With both variants, the view synchronization and the multi-view fusion are unified in the same framework and trained in an end-to-end fashion. In this way, the original DNN-based multi-view model can be adapted to work in the unsynchronized setting by adding the view synchronization module, thus avoiding the need to design a new model. Furthermore, the synchronization module only relies on content-based image matching and camera geometry, and thus is widely applicable to many DNNs-based multi-view tasks, such as crowd counting, tracking, 3D pose estimation, and 3D reconstruction.
In summary, the contributions of this paper are 3-fold:
- We propose an end-to-end trainable framework to handle the issue of unsynchronized multi-camera images in DNNs-based multi-camera vision tasks. To the best of our knowledge, this is the first study on DNNs-based singleframe synchronization of multi-view cameras.
- We propose two synchronization modules, scene-level synchronization and camera-view level synchronization, which are based on image-based content matching that is guided by epipolar geometry. The synchronization modules can be applied to many different DNNs-based multi-view tasks.
- We conduct experiments on multi-view counting and 3D pose estimation from unsynchronized images, demonstrating the efficacy of our approach. The remainder of this paper is organized
Selected Publications
- Single-Frame-Based Deep View Synchronization for Unsynchronized Multicamera Surveillance.
,
IEEE Trans. on Neural Networks and Learning Systems (TNNLS), 34(12):10653-10667, Dec 2023. [github]
Results
- Code coming soon!