- Comparison with State-of-the-art Trackers:
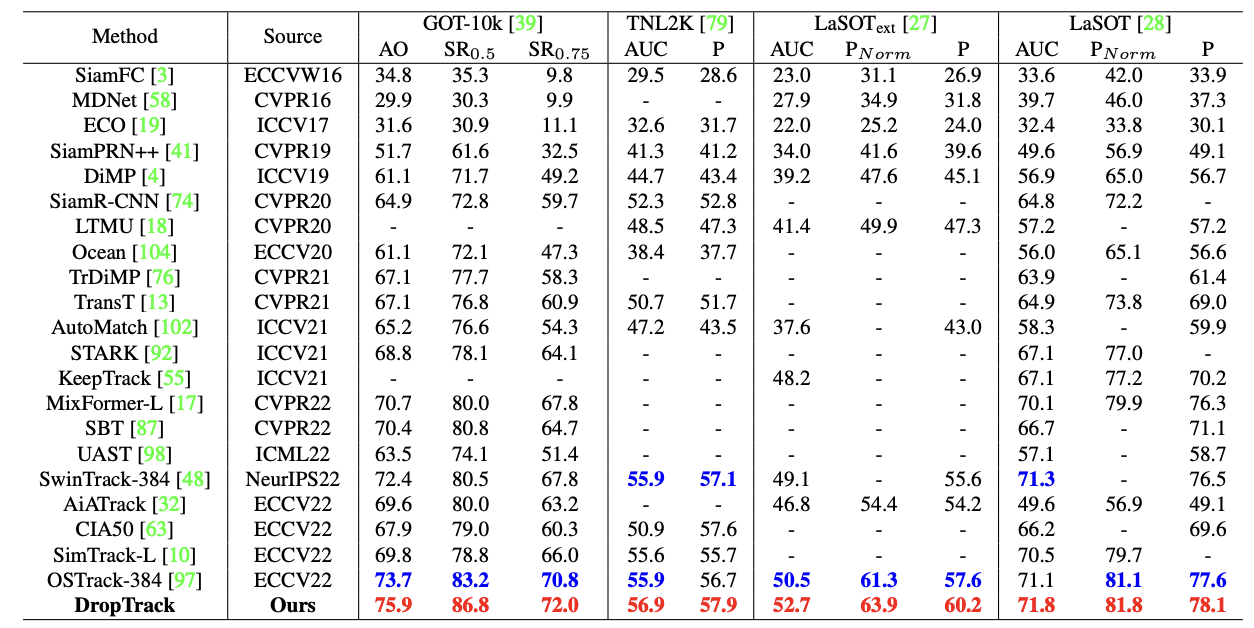
Table. 1: Comparison with state-of-the-art VOT approaches on four large-scale challenging datasets. The best two results are shown in red and blue. For GOT-10k evaluation, all the methods follow the one-shot protocol, training only on the training set in GOT-10k.
- Qualitative Comparison:

Table 2: Qualitative tracking results of our DropTrack and state-of-the-art tracking methods, including OSTrack, Ocean and SiamRPN++. The six video sequences are collected from TNL2K (from top to down are SportGirl_video_01_done, test_031_IronMan_transform_05_done, Monkey_BBC _ideo 01-Done, ZhuoQiu_video_02-Done, INF_crow1 and Zhizhuxia_09-Done, respectively). The frame number is shown in the top-left of each frame.
- Video Object Segmentation:
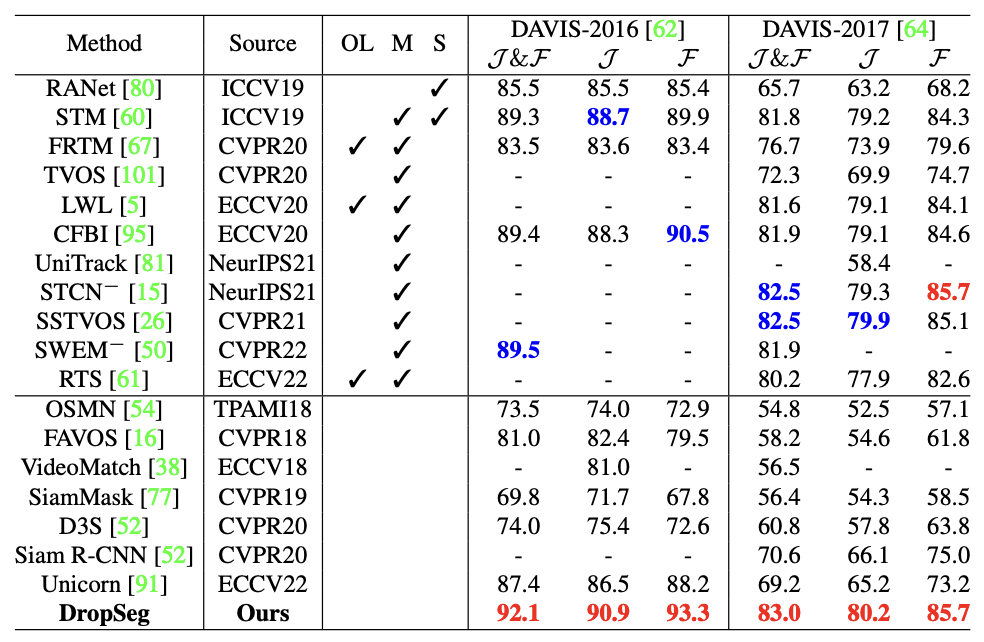
Table 3: Comparison with state-of-the-art VOS approaches on the validation sets of DAVIS-2016 and DAVIS-2017. OL, M and S indicate Online Learning, using Memory mechanism, and using Synthetic videos for pre-training.