Visualization
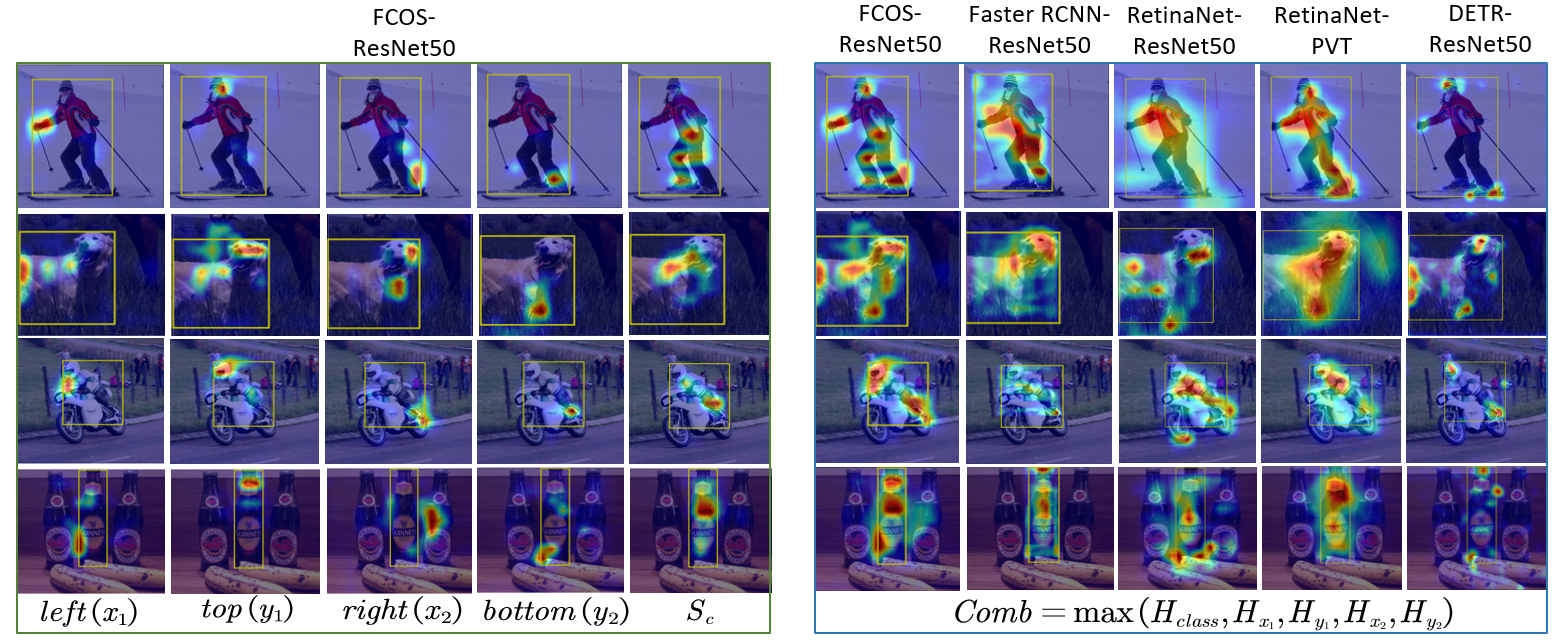
In order to verify the interpretability of visualizations, we generate visual explanations for different prediction attributes (class score, bbox regression values) using various detector architectures with the two types of backbones. To obtain a holistic view of the explanations generated by different models, we compute a combined heat map based on an element-wise maximum of heat maps for the predicted class and bbox regression, Comb = max(Hclass,Hx1 ,Hy1 ,Hx2 ,Hy2).
User Trust Study
We conduct two user studies. The first user study is on object specification, and tests the user trust of the detector based on the visual explanation maps generated by different XAI methods. The second user study is on object discrimination, and tests how well a user can identify which object the detector has detected and the user’s confidence.


The significantly higher human trust of ODAM demonstrates its superior instance-level interpretability for object detection at both aspects of object specification and object discrimination.
Faithfulness (Object Specification) Evaluation
We conduct a quantitative test on the object specification ability of the heat maps. A faithful heat map should highlight the important context on the image, which shows the ability of object specification. Deletion replaces input image pixels by random values step-by-step using the ordering of the heatmap (most important first), then measures the score drop of the predicted confidence (in percentage). Insertion is the reverse operation of Deletion.

ODAM has the fastest performance drop and largest performance increase for Deletion and Insertion, which shows that the regions highlighted in our heat maps have larger effects on the detector predictions, as compared to other methods.
Localization (Object Discrimination) Evaluation
Next we conduct evaluation of object discrimination via localization performance from the heat map. We look at comparisons of Pointing Game (PG) accuracy with ground-truth bounding boxes or segmentation masks, energy-based PG (en-PG) with box or mask, Heat Map Compactness (Comp.), and Object Discrimination Index (ODI). 
Both Grad-CAM and Grad-CAM++ perform poorly on both datasets since they do not generate instance-specific heat maps. ODAM yields significant improvements over D-RISE on all the metrics. Specifically, D-RISE cannot work well on CrowdHuman, which only contains one object category.
Odam-NMS Evaluation
Finally we evaluate ODAM-NMS, which uses the object discrimination of ODAM-train to remove duplicate detections. 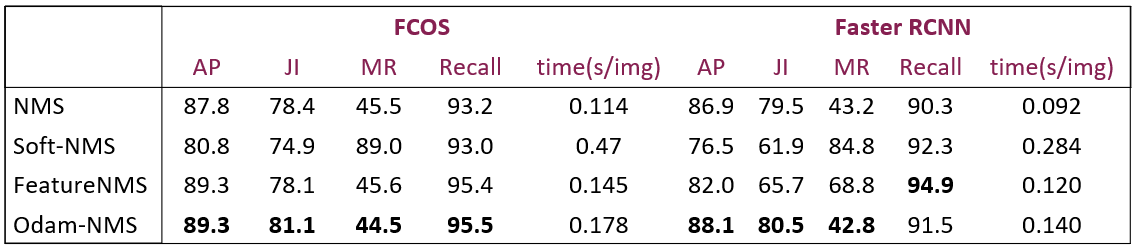
The results verify the object discrimination interpretation ability of ODAM with Odam-Train and demonstrate that the instance-level explanation for predictions can help improve NMS in crowd scenes.