Qualitative Results


Our method focuses on more of these aspects and generates accurate results. Our captions describe more properties of the main object, such as “black suit”, “red tie” and “a man and a child”. We also describe backgrounds that are distinctive, such as “pictures on the wall” and “city street at night”. In order to show the distinctiveness of our model, we present a similar images set with the same semantic meaning in the above figure.
Quantitative Results
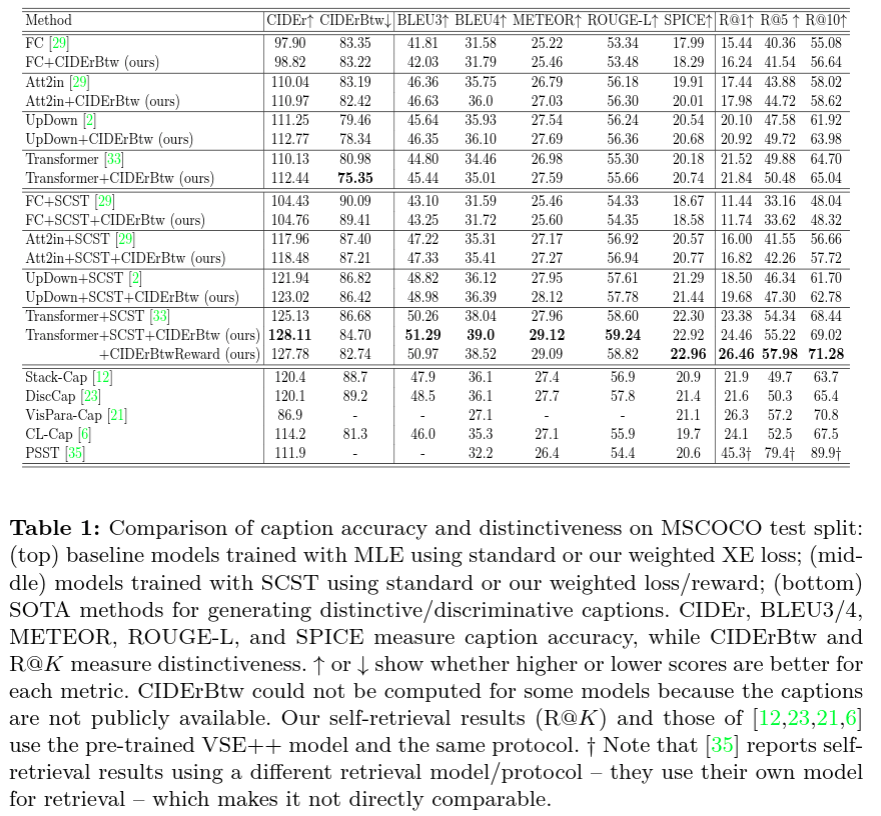
The main results are presented in the top and middle of Table 1. All baseline models obtain better performances when using CIDErBtw weighting in the training process, for both MLE or SCST, which suggests that our method is widely applicable to many existing models. Specifically, our method both reduces the CIDErBtw score and improves other accuracy metrics, such as CIDEr.

The results for the image retrieval user study are shown in Table 2. Compared to the baseline model, our method increases the accuracy of image retrieval by 5.6% and 14.4%.
The result for the distinctiveness/accuracy user study are shown in Figure3. From human perspective, captions from our models are more distinctive than the baseline models (our captions are selected 69% and 72% of the time). The improvement of accuracy is also obvious.