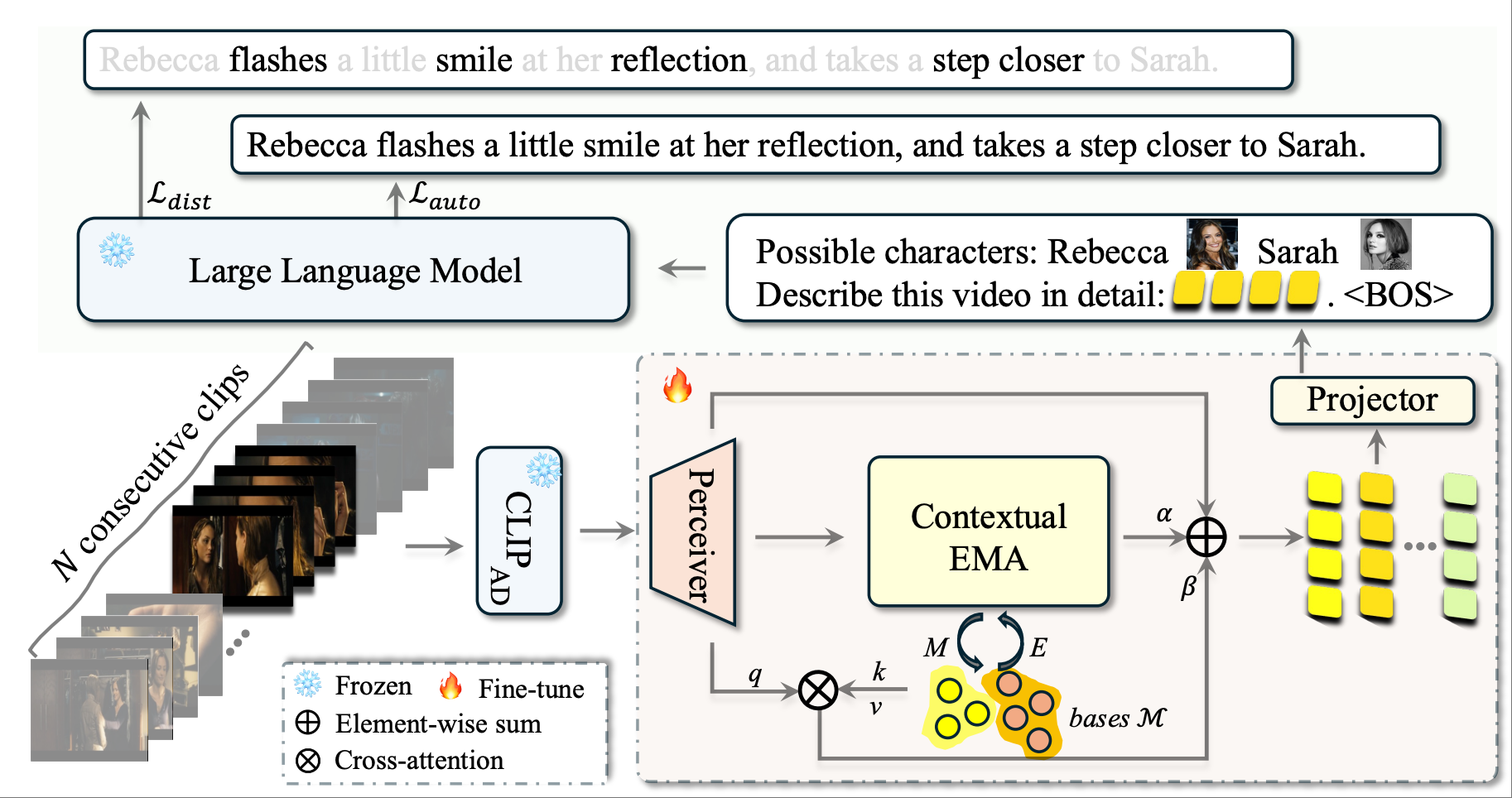
Audio Descriptions (ADs) aim to provide a narration of a movie in text form, describing non-dialogue-related narratives, such as characters, actions, or scene establishment. Automatic generation of ADs remains challenging due to: i) the domain gap between movie-AD data and existing data used to train vision-language models, and ii) the issue of contextual redundancy arising from highly similar neighboring visual clips in a long movie. In this work, we propose DistinctAD, a novel two-stage framework for generating ADs that emphasize distinctiveness to produce better narratives. Given the domain gap between the movie-AD and VLM training data, we first bridge this gap in Stage-I by adapting VLMs, such as CLIP, to the movie-AD domain. Our adaptation strategy is inspired by a key observation: AD sentences encoded by the CLIP text encoder can be effectively reconstructed using simple LLMs like GPT-2 with minimal fine-tuning, whereas AD reconstructions using CLIP visual features from the corresponding clips are often of poor quality. This suggests that while CLIP’s multi-modal embedding space is rich enough to represent AD information, its visual encoder is insufficient for extracting it. To mitigate this domain gap, we adapt the CLIP vision encoder to better align with the frozen CLIP text encoder using existing paired video-AD data. The alignment involves global matching at video-sentence level, similar to CLIP pre-training. A challenge arises because video clips are labeled with whole ADs, and words may not appear in every frame but must be aggregated over frames. Therefore, we propose fine-grained matching at frame-word level for this multiple-instance setting.

For Stage-II, we propose a novel distinctive AD narrating pipeline based on the Expectation-Maximization Attention (EMA) algorithm, which has demonstrated its efficacy in tasks such as semantic segmentation, video object segmentation, and text-video retrieval. Differently, we apply EMA to contextual clips from long videos, which often exhibit high redundancy due to recurring scenes or characters. By extracting common bases from contextual information, DistinctAD reduces redundancy and generates compact, discriminative representations that enable the LLM decoder to produce more distinctive ADs. To further emphasize distinctiveness explicitly, we introduce a distinctive word prediction loss that filters out words that repeatedly appear in contexts, ensuring that the LLM decoder focuses on predicting unique words specific to the current AD. With these two designs, DistinctAD produces contextually distinctive and engaging ADs that can provide better narratives for the audience.
Publications
- DistinctAD: Distinctive Audio Description Generation in Contexts.
,
In: IEEE/CVF Conf. on Computer Vision and Pattern Recognition (CVPR), June 2025 (highlight).