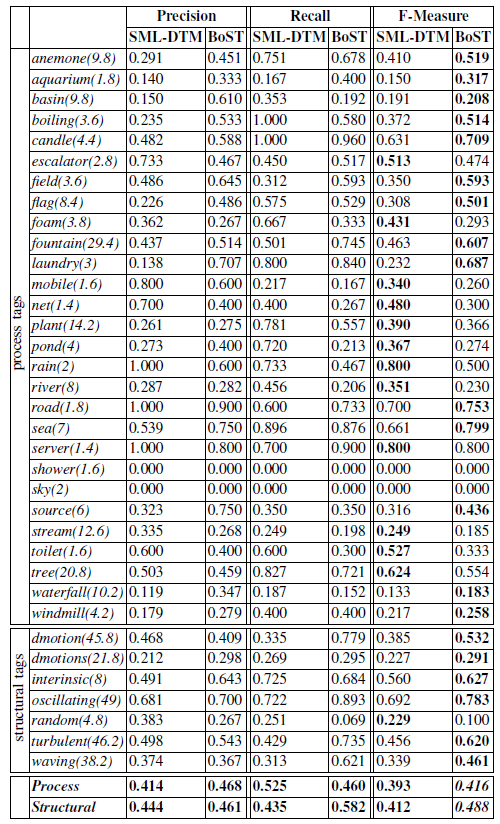
Here we test the BoSTree desciptor on video annotation of the DynTex dataset. Performance is measured using average precision, average recall, and average F-measure. In terms of F-measure, although BoSTree performs slightly worse than a BoS with large codebook, it is more than 9 times faster than BoS with large codebook.
Annotation results on the DynTex dataset:
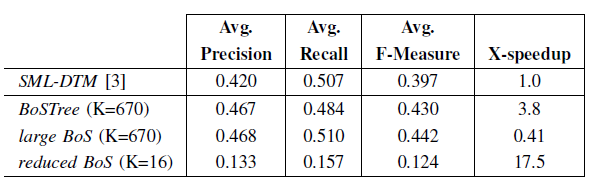
(a) Average precision/recall plot; (b) F-measure plot, showing all annotation levels, using BoSTree and SML-DTM on DynTex:
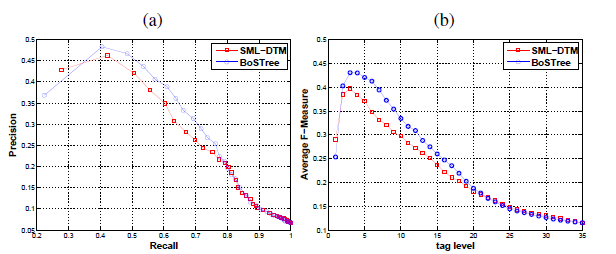
The following table shows the per-tag performance of BoSTree and SML-DTM annotation on DynTex. The average number of training videos available for each tag are in parenthesis. BoSTree typically performs better when there are more training examples for the tag. By BoSTree construction, tags with fewer training examples will have less codewords in the codebook, which may make it more difficult for the tag model to overcome noise in the descriptor.