Visualization Results
- Visual explanations are provided for the matching score between the image and the specific text prompts, which can be nouns (e.g., car, dog) or verbs (e.g., holding, standing). From the visualization comparison, Grad-ECLIP shows a superior explanation ability on different types of text prompts.

- The explanation map from Grad-ECLIP can also be generated from text encoder viewpoint. From the explanation of the sentence, we can identify which words are more important for CLIP when matching with the specific image, and conversely the text-specific important regions on the image are shown with image explanation. This word importance visualization of the input text can be helpful when designing text prompts for image-text dual-encoders in practical applications.

Quantitative Evaluation
-
Faithfulness Evaluation
A faithful explanation method should produce heat maps highlighting the important content in the image that has the greatest impact on the model prediction. Deletion (negative perturbation) replaces input image pixels by random values step-by-step with the important pixels removed first based on the ordering of the heat map values, while recording the drop in prediction performance. Insertion adds image pixels to an empty image step-by-step based on the heat map importance, and records the performance increase.
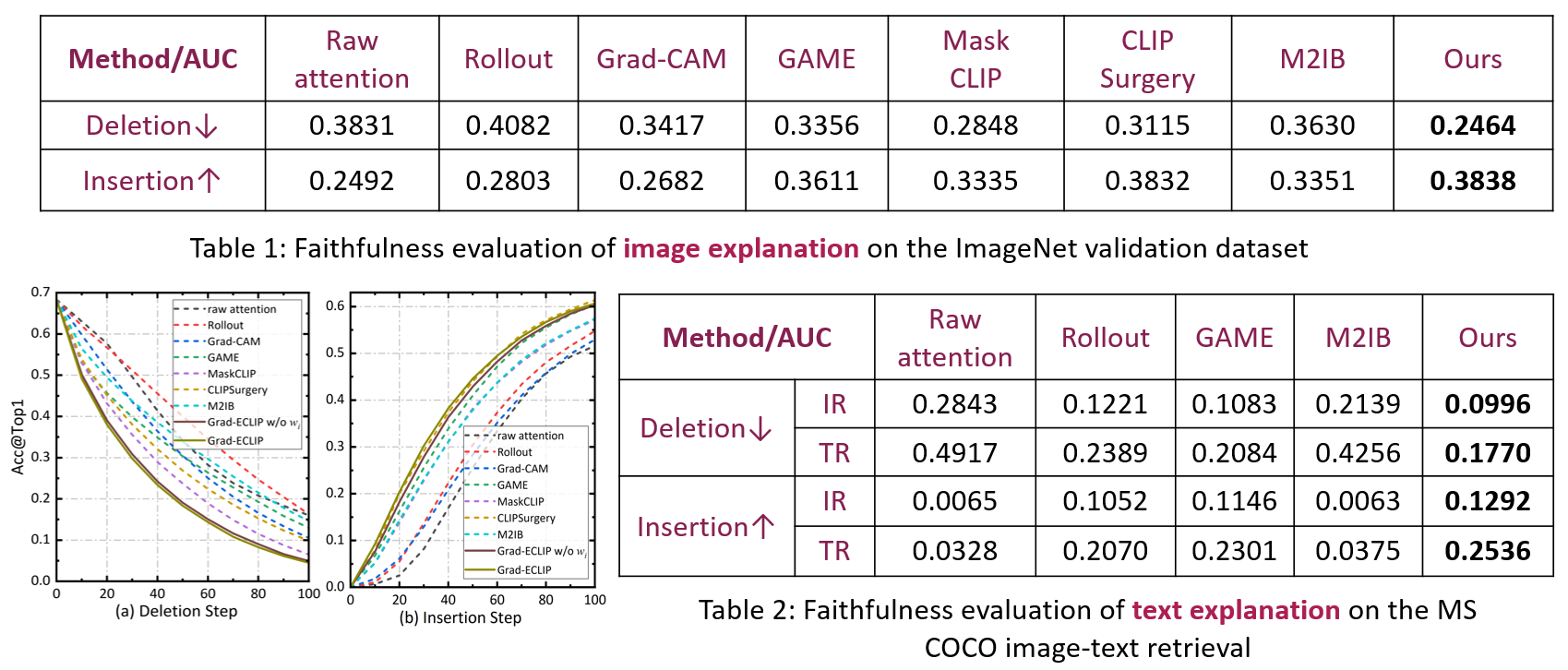
A steeper drop in performance with deletion steps corresponds to a lower deletion AUC, while the quicker increase in performance with insert steps outputs a higher insertion AUC. Our method obtains the fastest performance drop for Deletion and the largest performance increase for Insertion compared with most related works, showing that regions highlighted in our heat maps better represent explanations of CLIP.
-
Point Game and Segmentation Test
We next evaluate the localization ability of the visual explanations via Point Game (PG), PG-energy, and segmentation evaluation metrics, including pixel accuracy (Pixel Acc.), average precision (AP), and averaged mask intersection over union (maskIoU), regarding the heat maps as soft-segmentation results.
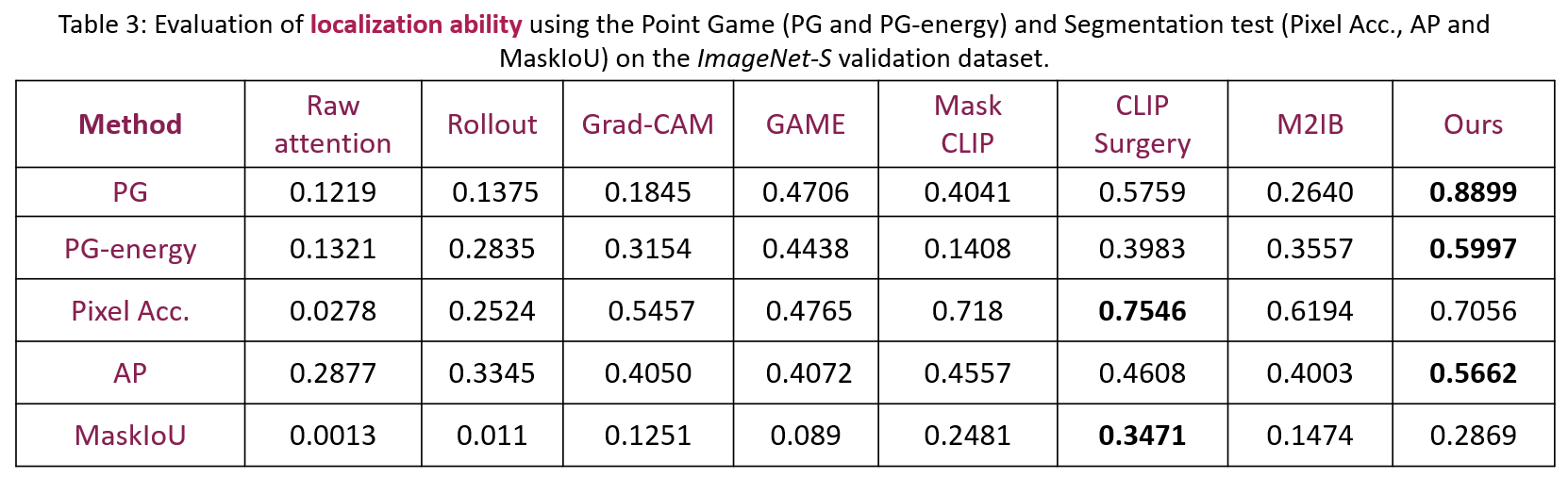
Grad-ECLIP significantly outperforms other explanation methods, especially on PG, which demonstrates that Grad-ECLIP can well show the attention of CLIP on the object with the correct category as the text prompt. CLIPSurgery obtains higher pixel accuracy and maskIoU since it tends to put high heat map values on all the pixels of the object region and gets a higher score when aggregating the heatmaps inside the object mask in these two evaluations. However, the lower PG, PG-energy, and AP demonstrate that there are more high values generated outside of the object boundary. Better segmentation does not necessarily result in faithful explanations, in terms of both insertion and deletion metrics, as indicated in Table 1.
CLIP Analysis via Grad-ECLIP

-
Concept decomposition and addibility in image-text matching
An interesting question is how it processes the combination of words, e.g., adjective and noun, verb and noun. We conducted experiments comparing the explanation heat maps for single words and combined phrases using Grad-ECLIP to examine the working function of phrase matching. From the experimental visualization results, we infer that when processing the matching of images and phrases, the model has the ability of decomposition and addibility of different concepts. This can help the model to generalize to different scenarios and could be the source of the strong zero-shot ability of CLIP.
-
Diagnostics on attribution identification
From the visualization results, we can infer that CLIP has advantages with common perceptual attributes like color, but cannot well handle physical attributes like shape and material, and is weak at grounding objects with comparative attributes, like size and position relationships. Related to the addibility of concepts in the previous section, it is reasonable to expect that attributes that have concrete visual appearance, such as color, will contribute more to the matching score, compared with the abstract comparative attributes.