These are examples of motion segmentation using the layered dynamic texture (LDT). We also compare to segmentations using mixtures of dynamic textures (DTM) or generalized PCA (GPCA). The video is available in both AVI format (DivX, playable with RealPlayer or Windows Media player) and Quicktime format (H.264).
Segmentation of Synthetic Circular Motion
These experiments were based on video containing several rings of distinct circular motion. LDT correctly segments all the rings, favoring global homogeneity over localized grouping of segments by texture orientation. On the other hand, DTM tends to find incorrect segmentations based on local direction of motion. In addition, DTM sometimes incorrectly assigns one segment to the boundaries between rings, illustrating how the poor boundary accuracy of the patch-based segmentation framework can create substantial problems. Finally, GPCA is able to correctly segment 2 rings, but fails when there are more. In these cases, GPCA correctly segments one of the rings, but randomly segments the remainder of the video.
circular pinwheel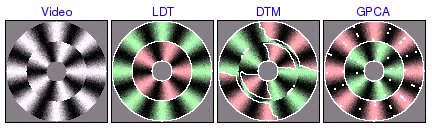 [avi (2.6 MB) | mov (1.6 MB)] 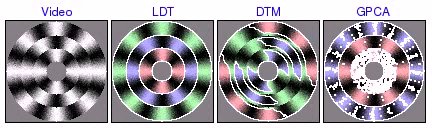 [avi (4.5 MB) | mov (2.8 MB)] 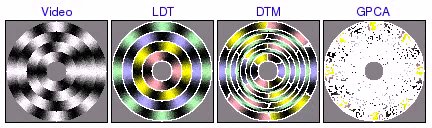 [avi (3.5 MB) | mov (2.0 MB)] |
square pinwheel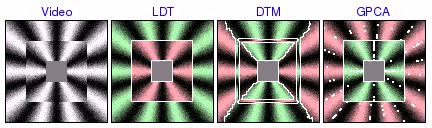 [avi (3.5 MB) | mov (2.3 MB)] 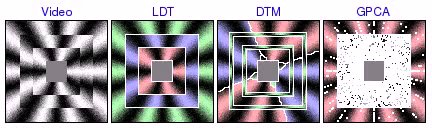 [avi (6.1 MB) | mov (3.9 MB)] 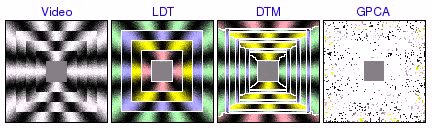 [avi (4.7 MB) | mov (3.0 MB)] |
square tracks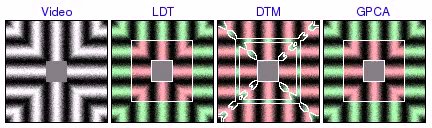 [avi (3.0 MB) | mov (2.0 MB)] 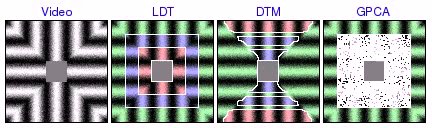 [avi (6.2 MB) | mov (3.9 MB)] 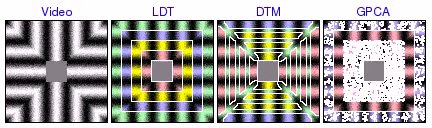 [avi (6.7 MB) | mov (4.2 MB)] |
Segmentation of Synthetic Texture Database
The synthetic texture database contains 299 videos of synthetic textures with 2, 3, or 4 segments. Qualitatively, LDT improves the DTM segmentation in three ways: 1) segmentation boundaries are more precise, due to the region-level modeling (rather than patch-level); 2) segmentations are less noisy, due to the inclusion of the MRF prior; and 3) gross errors, e.g. texture borders marked as segments, are eliminated. Full results are available for synthdb2, synthdb3, and synthdb4.
synthdb2: texture_050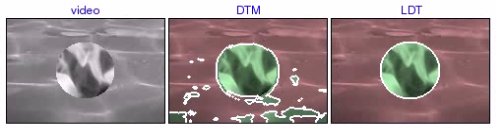 [avi (0.6 MB) | mov (0.4 MB)] |
synthdb3: texture_100 [avi (0.4 MB) | mov (0.3 MB)] This is an example where the DTM produces a poor segmentation (e.g. the border between two textures erroneously marked as a segment), which the LDT corrects. |
synthdb4: texture_098 [avi (0.3 MB) | mov (0.2 MB)] This is an example where the DTM produces a poor segmentation (e.g. the border between two textures erroneously marked as a segment), which the LDT corrects. |
synthdb3: texture_065 [avi (1.2 MB) | mov (0.9 MB)] This is a difficult case. The initial DTM segmentation is very poor. Albeit a substantial improvement, the LDT segmentation is still noisy. |
synthdb4: texture_032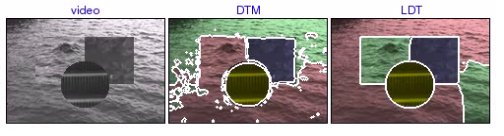 [avi (0.9 MB) | mov (0.7 MB)] This is a difficult case. DTM splits the two water segments incorrectly (the two textures are very similar). The LDT substantially improves the segmentation, but the difficulties due to the great similarity of water patterns prove too difficult to overcome completely. |
Segmentation of Real Video
These are examples of segmenting real video using the layered dynamic texture.
ferris wheel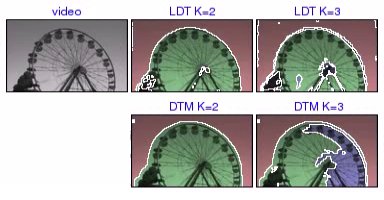 [avi (0.5 MB) | mov (0.3 MB)] For K=2, both LDT and DTM segment the static background from the moving ferris wheel. However, for K=3 regions, the plausible segmentation, by LDT, of the foreground into two regions corresponding to the ferris wheel and a balloon moving in the wind, is not matched by DTM. Instead, the latter segments the ferris wheel into two regions, according to the dominant direction of its local motion (either moving up or down), ignoring the balloon motion. |
mill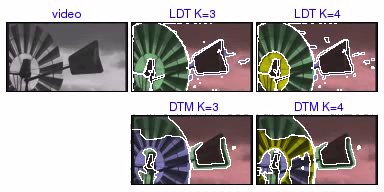 [avi (0.8 MB) | mov (0.5 MB)] For K = 3 regions, LDT segments the windmill into regions corresponding to the moving fan blades, parts of the shaking tail piece, and the background. When segmenting into K = 4 regions, LDT splits the fan blade segment into two regions, which correspond to the fan blades and the internal support pieces. On the other hand, the DTM segmentations for K = {3, 4} split the fan blades into different regions based on the orientation (vertical or horizontal) of the optical flow. |
whirlpool [avi (1.1 MB) | mov (0.8 MB)] This is an example showing the interesting property of LDT segmentation: that it tends to produce a sequence of segmentations which captures a hierarchy of scene dynamics. The whirlpool sequence contains different levels of moving and turbulent water. For K = 2 layers, the LDT segments the scene into regions containing moving water and still background (still water and grass). Adding another layer splits the moving water segment into two regions of different water dynamics: slowly moving ripples (outside of the whirlpool) and fast turbulent water (inside the whirlpool). Finally for K = 4 layers, LDT splits the turbulent water region into two regions: the turbulent center of the whirlpool, and the fast water spiraling into it. |
|
circular crowd (Mecca)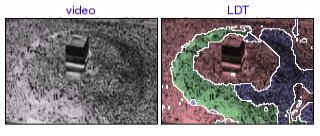 [avi (0.3 MB) | mov (0.2 MB)] A crowd moves in a circle around a pillar. The left side of the scene is less congested, and the crowd moves faster than on the right side. |
horizontal crowd (Mecca) [avi (0.3 MB) | mov (0.2 MB)] The crowd moves with three levels of speed, which are stratified into horizontal layers |
escalator crowd [avi (0.3 MB) | mov (0.3 MB)] A crowd gathers at the entrance of an escalator, with people moving quickly around the edges. These segmentations show that LDT can distinguish different speeds of crowd motion, regardless of the direction in which the crowd is traveling. |
highway onramp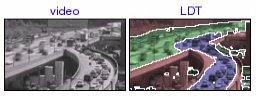 [avi (0.5 MB) | mov (0.4 MB)] The LDT segments a highway scene into still background, the fast moving traffic on the highway, and the slow traffic that merges into it. |
whirlpool (close) [avi (0.6 MB) | mov (0.5 MB)] A whirlpool, where the turbulent water component is segmented from the remaining moving water. |
windmill [avi (0.1 MB) | mov (0.1 MB)] A windmill scene, which the LDT segments into regions corresponding to the windmill (circular motion), the trees waving in the wind, and the static background. |
Synthesis Examples
This section shows several examples of synthesizing novel video from the LDT. First, an LDT was learned from a training video. Next the learned segmentation was used to assign regions to layers of LDT, and finally a novel video was generated by sampling from each layer. Qualitatively, the LDT synthesis is visually similar to the original videos, even when extrapolating past the number of frames in the original video. This indicates that the LDT is indeed a good representation for these visual processes. For each video below, the training sequence is on the left, the synthesis in the middle, and the learned segmentation on the right.
circular pinwheel
Examples of synthetic circular motion. The LDT was learned with n=2, and is capable of synthesizing the different speeds of the circular rings. |
||||
synthdb3: texture_027 [avi (0.6 MB) | mov (0.4 MB)] An example with three textures: two types of water and moving jellyfish. Note that the LDT (n=20) can simultaneously synthesize all three motions, which have distinct speeds. |
||||
synthdb3: texture_100 [avi (0.6 MB) | mov (0.4 MB)] An example with three textures: water, fire, and jellyfish. The fire texture is more stochastic than the smoother water texture, or fast jellyfish texture. The LDT was learned with n=20. |
||||
synthdb2: texture_066 [avi (0.6 MB) | mov (0.4 MB)] An example with two textures: fire and smoke. The fire texture is chaotic, while the smoke is smoother. Some small errors in the segmentation cause small artifacts in the synthesis (e.g. top-left of the smoke texture). The LDT was learned with n=20. |


