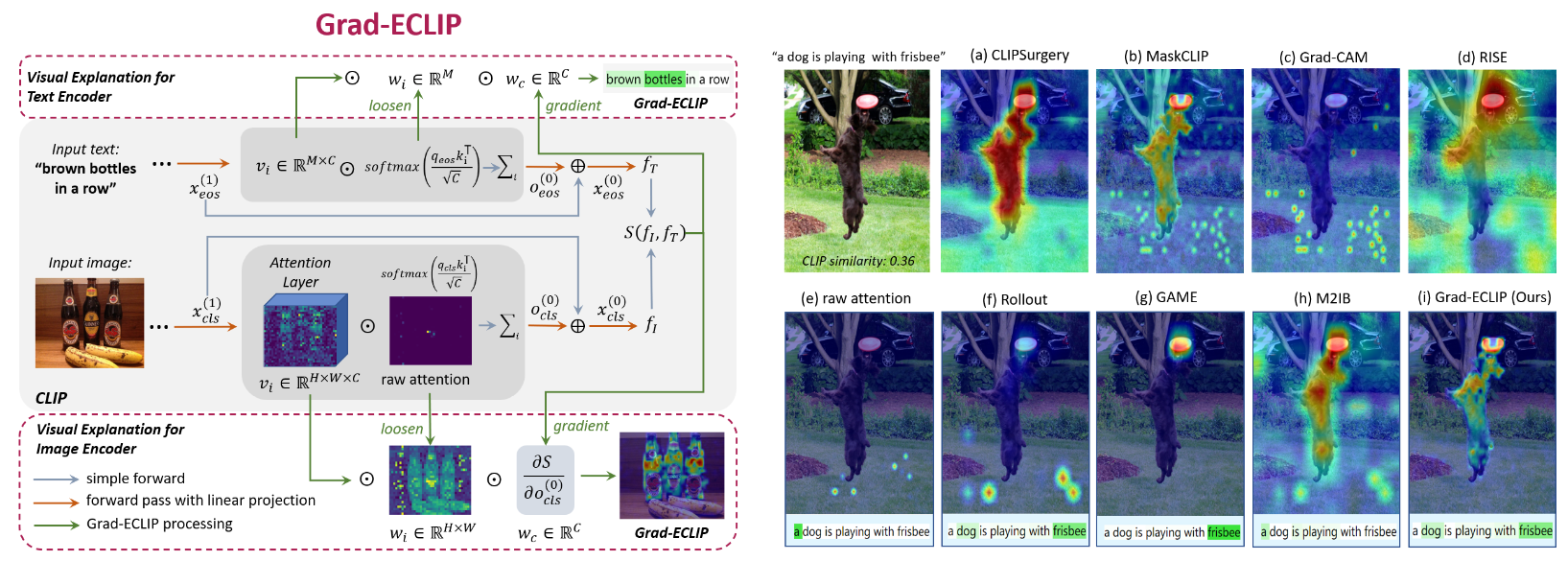
Significant progress has been achieved on the improvement and downstream usages of the Contrastive Language-Image Pre-training (CLIP) vision-language model, while less attention is paid to the interpretation of CLIP. We propose a Gradient-based visual Explanation method for CLIP (Grad-ECLIP), which interprets the matching result of CLIP for specific input image-text pair. By decomposing the architecture of the encoder and discovering the relationship between the matching similarity and intermediate spatial features, Grad-ECLIP produces effective heat maps that show the influence of image regions or words on the CLIP results. Different from the previous Transformer interpretation methods that focus on the utilization of self-attention maps, which are typically extremely sparse in CLIP, we produce high-quality visual explanations by applying channel and spatial weights on token features. Qualitative and quantitative evaluations verify the superiority of Grad-ECLIP compared with the state-of-the-art methods. A series of analysis are conducted based on our visual explanation results, from which we explore the working mechanism of image-text matching, and the strengths and limitations in attribution identification of CLIP.
Selected Publications
- Gradient-based Visual Explanation for Transformer-based CLIP.
,
In: International Conference on Machine Learning (ICML), Vienna, Jul 2024. [github] - Grad-ECLIP: Gradient-based Visual and Textual Explanations for CLIP.
,
arXiv:2502.18816, Feb 2025. [github]
Results
- Evaluation Results of Grad-ECLIP
- Code is available here.