Crowd Counting Results
These are the crowd counting results from Chapter 8. The video is available in Quicktime format (H.264).
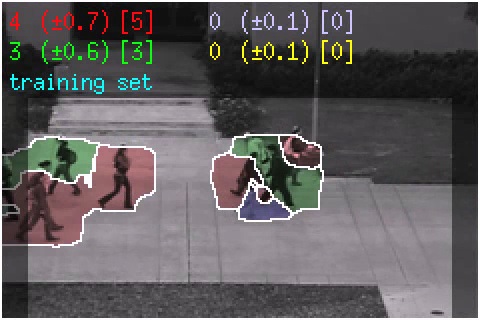
Peds1 Dataset (4000 frames)
This is a demo of the crowd counting system on 4000 frames from the Peds1 dataset. The system was trained on 1200 frames
to distinguish 2 crowd motions: "away" and "towards".
The red and green segments correspond to the "away" and "towards" crowds, respectively.
The corresponding counts are shown in the top left. The left number is the count estimate, the middle number is the standard deviation, and the right number is the ground-truth.
Finally, the frames marked as "training set" were used to train the GP regression model, and the region-of-interest is also highlighted. The video is
sped up to twice the normal frame rate.

[mov (35 MB)]
Note that this segmentation required no reinitialization at any point, or any other type of manual supervision. The sequences contain a fair variability of traffic density, various outlying events (e.g. bicyclies, skateboarders, or small vehicles, pedestrians changing direction, etc.) and variable environmental conditions (e.g. varying clouds and shadows).
Training Set Video
Test Set Video
Peds1 Dataset (1 hour)
This is a demo of the crowd counting system on the full hour of Peds1.
The system was trained on 2000 frames with ground-truth, and tested on the remaining 50 minutes video.
The video is sped up by 2 times, and each clip is about 3-5 minutes long.

[mov (36 MB)]

[mov (12 MB)]

[mov (33 MB)]

[mov (27 MB)]

[mov (21 MB)]

[mov (29 MB)]

[mov (21 MB)]
Peds2 Dataset (4000 frames)
This is a demo of the crowd counting system on 4000 frames of the Peds2 dataset. The system was trained on 1000 frames
to distinguish 4 crowd motions: "right-slow", "left-slow", "right-fast", and "left-fast".
The red and green segments correspond to the "right-slow" and "left-slow" crowds, while the indigo and yellow segments correspond to "right-fast" and "left-fast"
The corresponding counts are shown on the top. The left number is the count estimate, the middle number is the standard deviation, and the right number is the ground-truth.
Finally, the frames marked as "training set" were used to train the GP regression model, and the region-of-interest is also highlighted. The video is
sped up to twice the normal frame rate.

[mov (24 MB)]
Training Set Video
Test Set Video
Copyright
Antoni Bert Chan
2008
Peds2 Dataset (1 hour)
This is a demo of the crowd counting system on the full hour of Peds2.
The system was trained on 2000 frames with ground-truth, and tested on the remaining 50 minutes video.
The video is sped up by 2 times, and each clip is about 3-5 minutes long.
[mov (23 MB)]

[mov (8.4 MB)]

[mov (19 MB)]

[mov (17 MB)]

[mov (17 MB)]

[mov (17 MB)]

[mov (12 MB)]
People Detection Results
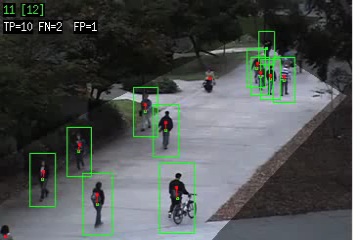
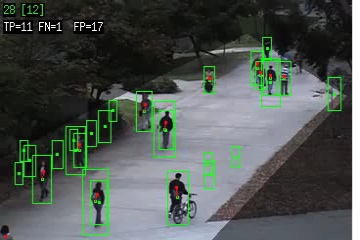
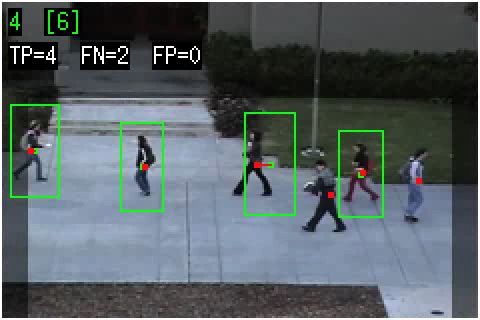
These are the people detection results on the Peds1 and Peds2 datasets (4000 frames each).
Each video shows the detections after filtering for geometric consistency, region of interest, and confidence.
The green boxes are the detection bounding boxes (the green square is the center). The red dots are the ground-truth people locations, and a red line is drawn to the matching detection box (if it exists).
The numbers on the top line are the detection count and the ground-truth (in brackets).
The second line shows
the number of true positives (TP), false negatives (FN), and false positives (FP). The two algorithms tested are HOG (Dalal and Triggs, CVPR 2005) and Deva (Felzenszwalb, McAllester, and Ramanan, CVPR 2008).
[mov (40 MB)]
[mov (45 MB)]
[mov (30 MB)]

[mov (29 MB)]